I’ve combined the example script with the era boosting script to create a low memory, “high performance” solution. I’ve tested it several times and total memory usage is around 13GB (edit: 16GB on data load, see post below). On an 8 core machine (no threads), it takes a little over an hour for the initial run.
Data is “int8”
The feature set is “medium”
Training Era = every 4th.
The era boosting portion saves each iteration as a model for additional testing and analysis. Parameters here are random, you’ll want to do additional testing
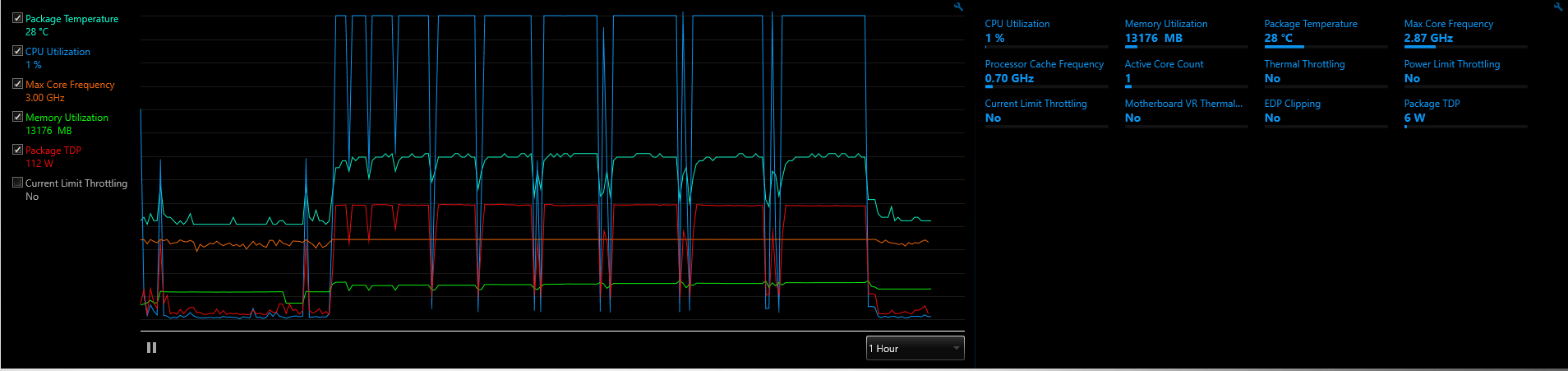
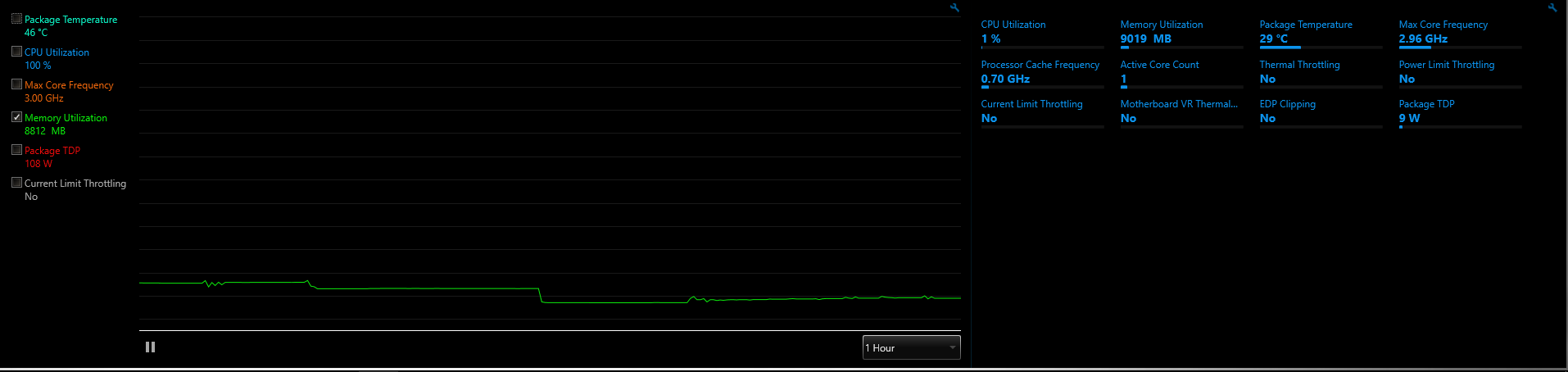
Just tested the script again on the bigger box which has some better diagnostics.
Using the “medium” feature set, this will just touch 100% of 16GB when reading the training data. It drops off to 13 and then creeps back to 15.4 during the run. If people run into issues we can create a slightly smaller feature set to avoid topping out.
Using the “small” feature set, you’ll see just under 10GB of mem utilization during a run.
I’ve cleaned up the code a little, put things where they belong. Still have one thing I need to sort out and will get to that this week.
I’ve started working on an optimized feature set that will target around 15GB, leaving a little more headroom when loading the data. I’m using MDO’s BorutaShap code for this, it’s going to take a while. Estimating around 250 hours to process all the targets. I’m going to publish all the results from this as I feel like the community at large will benefit from the knowledge, it also prevents us from doing parallel work, which I’m not a fan of. No reason to be wasting compute cycles on the same stuff when we should be focusing on original/different ensembles. I’ll drop the first half this week and the balance next.
I’ll make this a priority the first of the year when the new data drops, so we can hit the ground running.
Speaking of ensembles, it’s never too early to begin to think about the possibilities. Between the current number of targets and the growing feature set, we should be able to generate a large number of “unique” submissions. They’ll still be correlated to some degree or another, but the opportunity here to generate “true contribution” should be high (once we know what it is of course.)
This code was ripped from codegrepper.com I remain little more than a python sneak-thief.
from itertools import combinations
# targets
targets = [
"target",
"target_jerome_20",
"target_janet_20",
"target_ben_20",
"target_alan_20",
"target_paul_20",
"target_george_20",
"target_william_20",
"target_arthur_20",
"target_thomas_20",
"target_nomi_60",
"target_jerome_60",
"target_janet_60",
"target_ben_60",
"target_alan_60",
"target_paul_60",
"target_george_60",
"target_william_60",
"target_arthur_60",
"target_thomas_60"
]
ensembleLength = 6 # pick any number here from 1 to 20
for i in combinations(targets, ensembleLength):
print(i)
Boruta classifies features as ‘confirmed important’, ‘confirmed unimportant’, and ‘tentative’. I grabbed 400 random features from the 1015 ‘confirmed unimportant’ group on nomi_20 and generated a model with decent results. Unimportant isn’t the same as useless.
There have been a couple of targets where the actual features weren’t more predictive than the shadow features, so there are no “important” features in those (Paul, Janet). Seven targets down, 13 to go.
As of right now, there are just over 300 features that fall into the “strong” and “weak” Boruta classification.
I’ve just updated the repo with a new feature file that contains 300 features from the Boruta run. These features should work on a 16GB machine and leave headroom in the commit charge on a Windows machine.
From “features2.json” use “xlsmall” for the 16GB feature set.
I’ll continue to add alternative target output from the Boruta run as it drops. This feature set should get you going though.
I generated a small batch of nomi_20 models last night with the intermediate script and the new feature set. I’ve pushed these up to a public S3 bucket for anyone to grab and investigate. They will run from extremely under-fit to (probably) extremely over-fit and should give deeper insight into the Boruta optimized feature set and the characteristics of this modeling approach.
This should help reduce some of the initial time spent creating and researching the models and get you closer to generating your own work, interesting ensembles, and alternative target modeling.
Models developed with:
Max Depth of 3, 4, 5 & 6
Num Estimators at 500*
Col Sample at 0.1
Learning Rate of 0.001
Num of Iterations at 22*
These are completely random, there are likely better parameters.
Each file follows a naming convention of
Max Depth as md
Num Estimators as ne
Num of Iterations as ni
Target name Ex. md3_ne500_ni0_target_nomi_20
Thank you very much for your work.
The URL listing is truncated. I am sure it is possible to construct them all (semi) manually, but is there a way to bulk download them all (one file) or have the URLs listed sequentially?
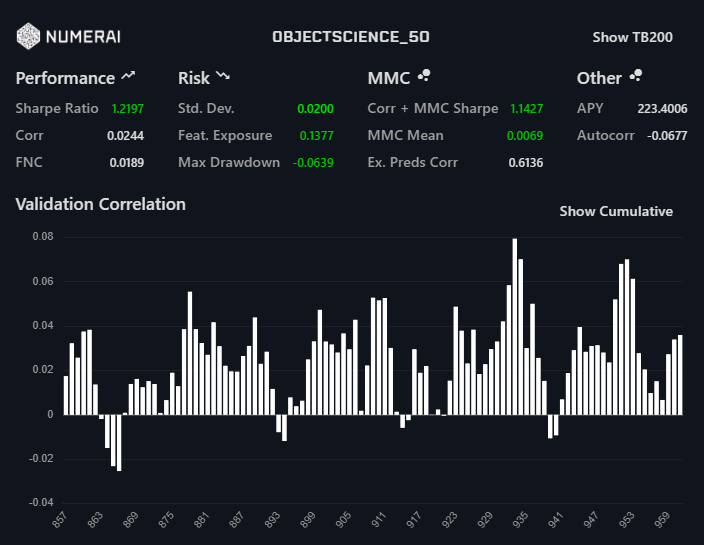
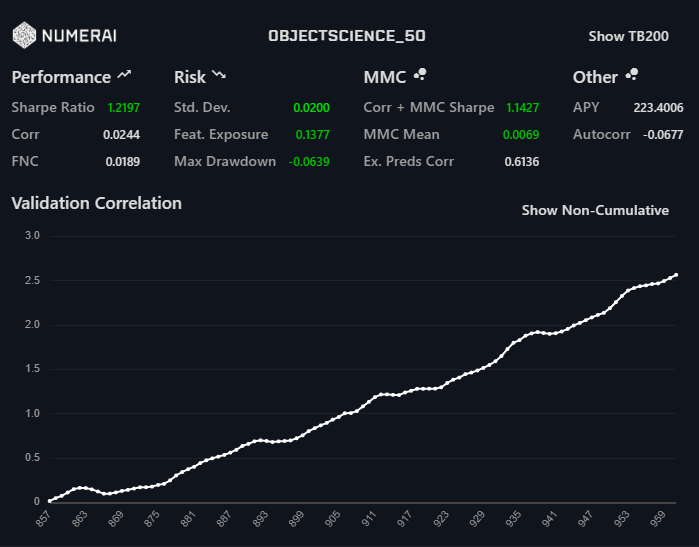
This is really cool, and a lot of great work. One thing that stands out to me is the trial you posted above that attains almost 5% average correlation, that is huge, right?
I’ve been playing around with feature neutralization in my own work and wanted to pass along some ideas that will work with our sample models. These aren’t recommendations, just random outtakes to get you thinking in new directions.
From our models I grabbed:
ni20_target_nomi_20
ni15_target_nomi_20
ni10_target_nomi_20
ni5_target_nomi_20
I ran each of these models through a series of neutralizations:
100% of the features neutralized by a factor of 1.0
100% of the features neutralized by a factor of 0.75
100% of the features neutralized by a factor of 0.5
100% of the features neutralized by a factor of 0.25
I repeated this process for 75%, 50%, and 25% of the features for all of the selected models.
You can see sample results for each model here.
From here I selected a single iteration (ni) from each modeling group, based on its highest APY with a minimum Sharpe of +1.0. These selections are noted by an " * " in the linked table.
The only exception to this is the selection as at " ** ". When I reviewed the choices, I had two from “Neutralize 0.25 features…” and none from “Neutralize all features…” The OCD in me insisted at that point I must have one from each group and " ** " was used instead…
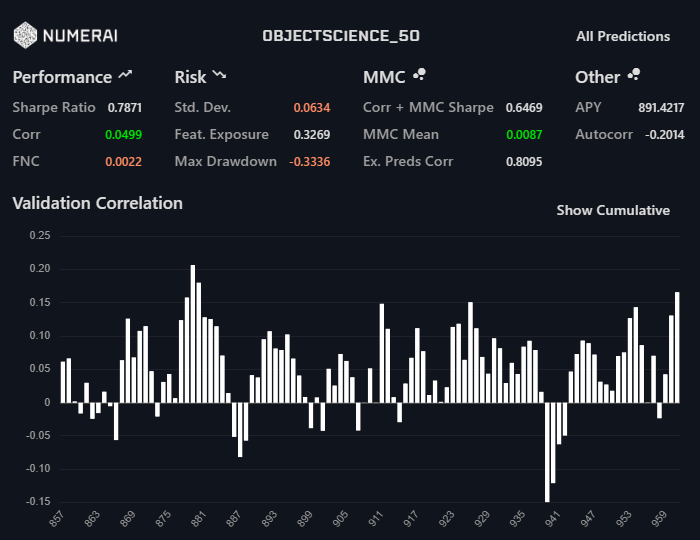
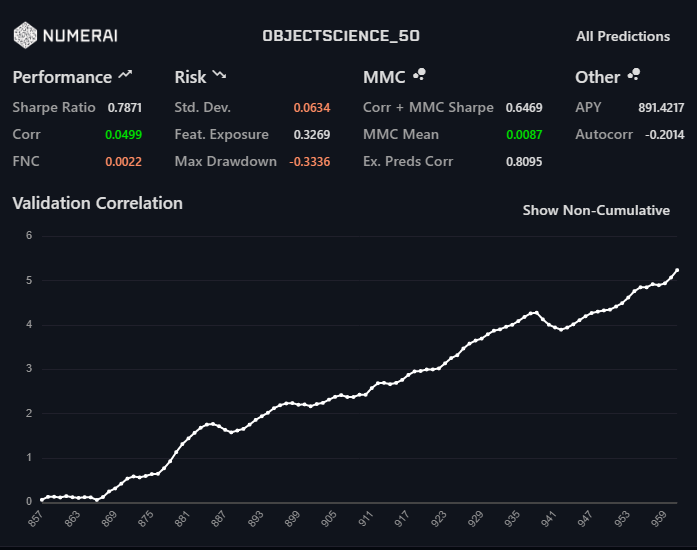
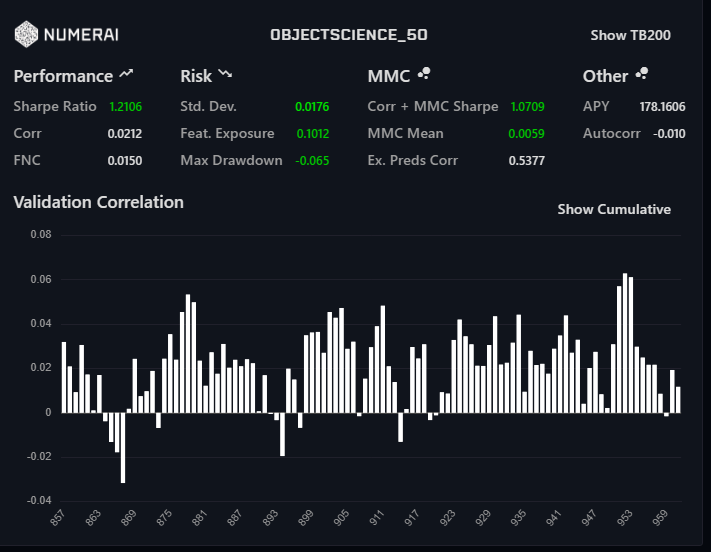
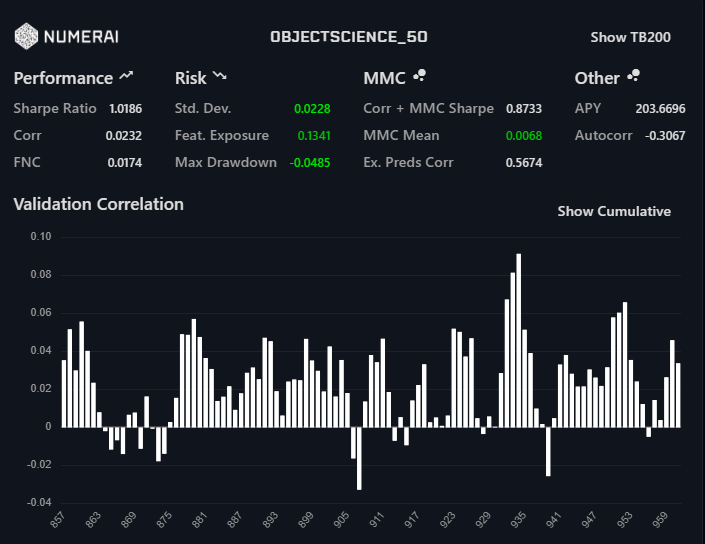
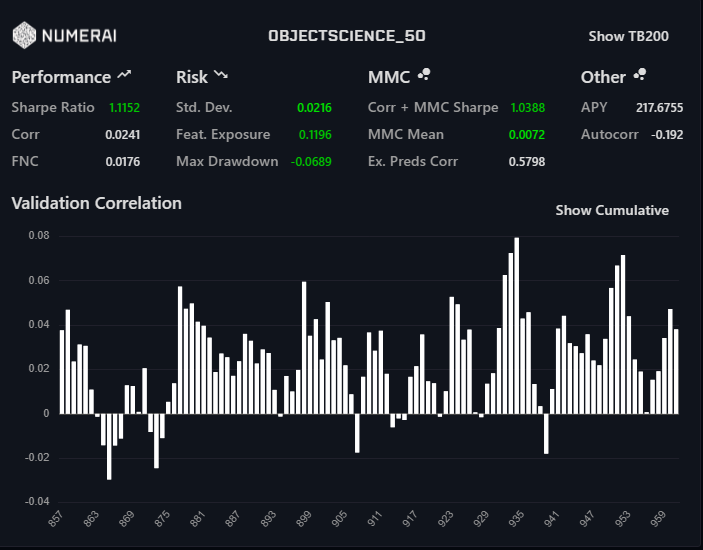
Those results were ensembled and this is the result:
I hope there will be room for models like this in the competition for a long-time. When the new data drops and I get my initial work finished, I plan on duplicating this if at all possible. In a perfect world, we can generate two or three 16GB feature sets and corresponding model sets. This will allow for a lot of creative ensembling.