0.047577065889401226
That is a really high cv score, is it a tree-only models or it mixed with NN too?
It is really interesting that your validation is that low, so i guess it is a very NN-heavy ensemble? I bet the sharp ratio will not be that great. After they switched to TC, i think you need to change the ensemble selection rule.
its a boosted NN.
(this text takes the post beyond 20 chars…)
sharpe is very low.
(to get the char count past 20…)
Thanks for the infos, would you mine also provide me with your sharpe?
1st for corr, 3rd for mmc
0.0469 From a scrap of paper. Can re-run when I’ve finished my HW.
You mean 0.0469 for sharpe?!
Yeah… i think so… i scribbled it on a sheet of paper but i think that’s correct. i’ll re-post on sunday when i’ve got the next round’s data.
Are you sure? 0.0469 for Sharpe is extremely low…
i’m certain its correct. will re-post sunday’s calculations. i get that its extremely low which is another reason i’m puzzled at the models performance. i’m doing a write up, trying to explain why i ran with it when on paper it looks to be a lame duck.
1 Like
Cant wait to see it, it is very interesting!
0.0469 is your validation sharp right? I am curious about what you cv sharp is.
imo…training dataset is enough informative to deliver kind of solid results in diagnostics tool and validation data (without data leakage)
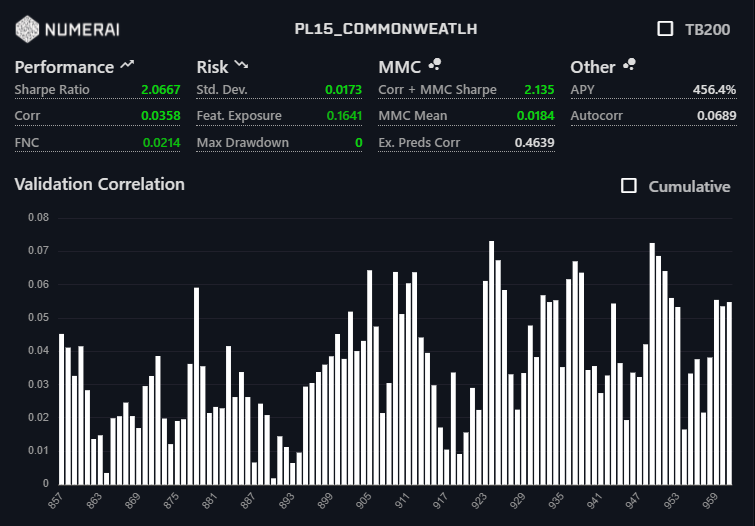
Another story is to prove it on the live data which I can’t yet, as being a new participant in the tournament.
And I agree more data would make us more confident about our work.
@kowalot I’d double-check on that whole “without data leakage” thing (also check you aren’t including any of the targets as features in your training). The probability of the above results being genuine from an uncorrupted model are extremely small.
@wigglemuse , Ok, I will double check.
My quick checks:
- model is trained on training data(no CV with validation data)
- validation data are only used for early stopping (different structure)
- target is in separated structure
- additional targets are kept in different structure and not used in this specific configuration
- only selected features are available by the training loop (“feature_”)
- assertion of dataset indices between training and validation sets
- the same code works on predicting tournament data (where certain data are unavailable)
If you see another common pattern of data leakage which I am not aware, please advise me.
I believe that the most controversial is max_drawdown. Am I right?
This is what i tried to optimize during last week (several negative hard validation eras 864,921,922, 945).
Normally max_drawdown is somewhere between -0.01 and -0.06.
Well, yeah, you’ve got no negative eras and that’s just not gonna happen if it were truly blind to that data. However, you are now saying you were optimizing for the hard validation eras which is leakage by another name so there you go.
1 Like
My previous models have several negative val eras I changed the architecture to get rid of them. Validation data are used ONLY to stop/select certain snapshot of model (and it’s not max_drawdown). Do you suggest I should do stop of the training process based on another spare/untouched part of training (in our case pretty similar to the rest of training data as it’s one countinous block of eras)? How do you do early stopping?
No, I mean it SOUNDS fine, maybe. With enough parameters you can get anything to fit anything. Your validation results are very suspicious, though. But they are not SO outrageous that I’d say that it is just absolutely positively totally impossible (even though I kinda think so). We’ve seen some where we know there was leakage or target training that are twice as good as even that. Because we don’t actually know the upper limit of what’s legitimately possible there is always the very tiny chance that you’ve done something brilliant and magical, but really they look way too good to be true and I wouldn’t trust them. Needs to be seen on live data. But hey, even if there is some “cheating” going on and these results are exaggerated that doesn’t necessarily mean the model is crap, just that it isn’t this good.