Chinese Content:
新开一个帖子。让使用中文的朋友一起聊聊 NUMERAI 以及 SIGNAL. 互相协助,共同进步。
Chinese Content:
新开一个帖子。让使用中文的朋友一起聊聊 NUMERAI 以及 SIGNAL. 互相协助,共同进步。
大陆现在严管影响你们资金进出和参与竞赛么?
哈哈。找到一个使用中文的朋友了。 我在新加坡。
来了,正在入门中,这个能真金白银的干吗?出入金怎么搞啊
Chinese content:
从现在的系统表现看, 好像可以真金白银的干。NMR 可以出金到个人的钱包。 如何到个人的银行账户,就看自己的造化了。 不过还没点到点试过。
可以,准备开搞,这个有 对接 实时(美股)股票市场 还是虚拟币?
emmmm 放弃了,不准备搞了,我还是回去A股量化吧,这个还要注册用AWS
chinese content.
可以先从 Tournament 开始。市场数据已经准备了。 只需要自己搞一个后台的计算模型,每周发送预测就可以。 我用 AZURE ML STUDIO (free) 就可以了。 至于 SIGNAL 讯号, 可以慢慢来。 这个对全程的数据处理,要求会高一点。
给力啊,终于有中文的了.同志们互相分享一起起飞啊
Chinese
有什么问题,可以讨论一下。
潜水的,冒个泡。
祝各位NMR财源广进 
Chinese 希望以太币和 NMR 的价格 能稳住。不要太低或太高。
歡迎你們😬 我是Numerai的CTO. 重香港長大但中文不太好。請多多指教。
有什麼我能幫忙或解釋的地方可以直接問我 
感谢回复。接触 numerai 几周时间,但从各位的零零碎碎的回复中,学到很多东西。也感谢论坛一路来的支持。
老kaggle发烧友, 从2016/2017年开始关注Numerai, 20+个features的时候玩过一段时间后就断了几年回去kaggle上继续比赛了。不过这几年一直有关注Numerai的进展,觉得skin in the game是个非常有革命性的概念。
去年好朋友看玩得很好,很是羡慕 - 所以今年几个月前我自己有开始入坑了。 现在从数据上,比赛的形式上,社区的建设上, 觉得都做得很好。 和几年前比觉得是进步真是很大的。
以后会继续积极参与 

请问大家有什么好的方法提高模型表现么?我先分享一下我做的:
因为刚做这个不到两个月,所以还有很多可以尝试的,接下来准备尝试换loss function尝试,还有将era按表现分组进行训练
这是我现在模型的表现…离做的好还是有很大的距离,signal也在做,现在表现不是非常好,只有120%APR…做这个真的有些时候挺费时的,希望使用中文的朋友一起分享自己的提高方法,我们一起提高模型表现!
感谢分享。
数据分析不是我的专业,所以在建模上,还是严重依赖我所使用的工具 - Azure Machine Learning studio.
有使用 feature filter 的功能,选择了150个参数。也使用了 Hyper Parameter 对树模型进行优化。还没有找到使用 Azure ML studio 做参数中和的自动化的模块链接。
每次递交validation的结果,大多是黑色,或者红色。还没看到过绿色。
在 signal 方面,好像结果比 tournament 要好。由于我做外汇交易,所以选取了在外汇交易终端有数据的 300多个股票。可以直接利用终端的指数建模。现在每周提交的 APR 很高。但实际交易结果则有上有下。还需要观察。
请问一下signal建模你都用哪些feature呢?我自己现在只用了rsi,macd和sma作为输入,有什么别的指数或者signal可以参考么?
我使用了Oscillator 指标, 在多个时间空间维度上采集数据建模。APR 有 700+. 感觉 overfit .
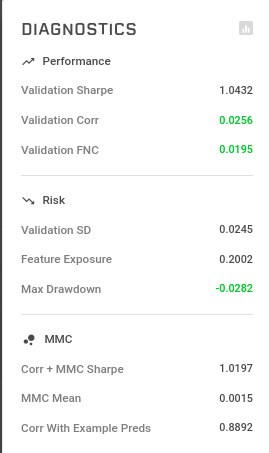
谢谢大家的分享, 我这里分享一下我的validation的方法。主要的idea是尽量利用validation1和validation2 之间的ratio,同时侧重考虑val2的corr和sharpe. 以下这图是我参考的metrics
我发现如果光是一 val_corr或val_sharpe来做参考值的话,有时会出现val1 corr很高,而val2很低的情况. 考虑到val2来源于train+val1后好几年的数据, 直觉就是val2 corr 和sharpe相当要靠谱一些。 另外就是尽量找va1/val2 corr ratio 或这va1/val2 sharpe ratio比较低的, 也就是说重点找一些能稳定预测n年后数据的模型。
在此之上, 再加上live rounds上的表现来进一步评估。 目前发现我的模型在live rounds上的表现和以上的表格还算吻合, 有几个比较不符合这个规律的,还有待进一步观察。
总之, 我的特征选取和目模型参数目前都是按这个方式做。 没怎么做特征工程,可能有时间会补一下。