Your validation diagnostics is really horrible… I think it is a dangerous sign as it is evident that your model at least performs very poorly in the validation period (which may happen in future). We cannot trust the validation result 100% but it does not mean we need to ignore it.
3 Likes
I agree that CV done properly is better than a fixed validation set as effectively your model has been tested on multiple validation periods which is a better evidence for the performance/generalizability of your model. But when you use your nyuton_test8 4 months live performance ranking as evidence of good model but ignore 2 years period performance of validation set… that seems a bit odd.
So, IMO the evidence ranking is CV (if “effective validation period” longer than length of validation period) > Validation > Live (if less than the length of validation period)
Totally agree. I wouldn’t stake my life’s savings on it but… it performs [mostly] quite well. This round has since garnered two gold medals , since March it has dipped into the red on only 4 occasions. I appreciate the comment and some of that will find it’s way into my write up though Tbh it doesn’t matter if it succeeds or not as I’m doing this for an A level EPQ (UK) and I choose AI ![]()
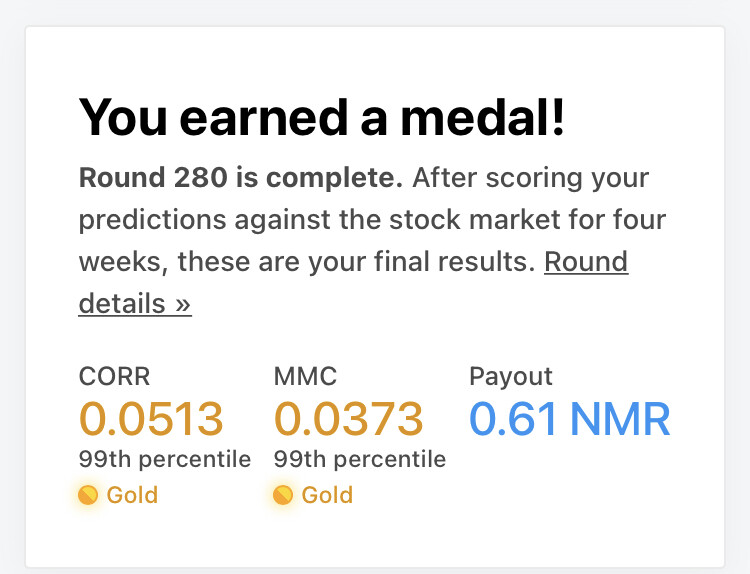
3 Likes
This is Grinning_cat’s old and new diagnosis:

For a model that ranked 15th in 3 months return at time of writing, corr2mmc sharpe usually between (rank 10-60), and have not had a burn round since creation at round 263, it isn’t too bad ![]()
4 Likes
how does this model perform on the “old data new val” validation set? if you don’t mind sharing 
I haven’t done that but I will when I get a mo and I’ll post the results 
1 Like
The problem here is that validation data aren’t representative, they are very bad eras in average. So when you train using only train set and validate the performance against validations, results are bad, but it isn’t a serious problem: as validation isn’t representative, when you put the model in real markets it works pretty well.
You can use validation as ‘the worst scenario’ and using them in training (with careful), adjust a very robust model, that works worse in normal periods but lose less in ‘similar to validation’ periods.
For use a better validation framework we would need the targets for the period between train and validation. Having them (not only the hell of the validation dataset) we could fit a more realistic model for an average market condition.
3 Likes
And… it’s finally breached the top 100 for correlation. Been in the mmc hot 100 for a while now.
1 Like
Great thread here @nyuton. I seem to be on the other side of the problem. In fact I choose some best params based on cross validation and then train using those params on the whole train data, check the validation metrics (corr and MMC both 100th percentile), so CV AND validation metrics good, but live performance seems mediocre at best, although too few rounds to know for sure.
1 Like
Now 32 for corr, 24 for mmc.
I have experienced this also and thought, this is a rubbish model I have built but end up getting a very good score in production. I still think the scoring guideline is still very useful. Perhaps for conservative modelling and newbies may be best to trust the diagnostics until you rich @nyuton-level mastery and then probably you don’t need to look at the score. It is afterall an art as well. However, the riskier models may do very well, but perhaps over a shorter time frame. @nyuton How long have you been running #39 for in production?
A general question. What’s the value of cross validation, if we already confirm the prediction model, say XGB. Should hyper parameter, neutralisation and feature filtering be more important than CV ?
It’s 30+ rounds by now. Still in very good position.
1 Like
Just a heads up: the three different validation diagnostics you can get with legacy data may differ significantly. For example, here are three different diagnostics outputs from the same model.
Old target:

New target, old validation set:

New target, new validation set:

-0.01 from old diagnostics to new. I don’t have too much live data right now, so we’ll see how it actually translates into live performance.
15th for corr, 8th for mmc
5th for corr, 5th for mmc
It is really good! Since your validation score is so bad, I am curious what your CV score is.
It’s a miracle… What cv score would you like to see?
I am guessing your CV score should be very high, at least 0.045+ corr?
i’ll re-run everything this afternoon for this week’s round and post 'em. TBH i can’t remember as i’m working on some other models and this model runs on auto-pilot.