You’re still scored on regular targets in the main tournament, and mmc will be scored on feature neutral targets. You just choose if you want to use the new targets to supplement your training or not.
Feature neutral targets may be at a disadvantage in some ways, but they should be lower risk as well, given less simple exposures. You may see lower returns but higher sharpe in your tests.
It’s also worth considering if you think simple linear factors will continue having an edge or not in the future. If you think not, why not just remove them all before hand so your model doesn’t learn them?
Right. So I understand we don’t want to be suckered by the easy lure of superficial linear correlations that may be fleeting. But, do we really have hard evidence that deeper features are necessarily more robust? After all, by the very fact that they are more complex (at least given the dataset with the features we have), involving interactions between features – couldn’t it be that they could be quite brittle if those interactions don’t hold up era-to-era?
Undoubtedly some of the linear features that do great in specific eras are just lucky/random and should not be relied upon (I think that’s been proven by you and it has been proven by me in my own testing), and it makes sense to remove the gravitational pull of those when making models (which I already do in my methods although I don’t totally eliminate linearity). But as most of us know, modern techniques beyond simple parametric models with find a “signal” in anything even if it isn’t there, linear or not. So while I think this will be very interesting and useful, getting rid of linearity in and of itself will not prevent overfitting or possible reliance on fleeting/fickle factors – it may even cause more of it. So there are going to be some new gotchas there I bet.
(None of this is meant as criticism, just musing.)
Thanks for the write up Mike! There’s something that has been bothering me about the relationship between the feature neutralization operation and the feature exposure metric that I’ve been trying to figure out how best to explain, but I think I’ve got it now and I would love to hear the thinking about it on your side of things. The problem is that they aren’t exactly related and the feature neutralization operation is not actually a minimizer of the feature exposure metric. The easiest way to see this is if you assume you have a model whose predictions have a correlation of 0.1 with every feature, it’s feature exposure metric would be 0 and impossible to minimize further, while the feature neutralization would then remove those correlations and could only increase the feature exposure metric. The feature exposure metric measures the dissimilarity of correlations across features, while the feature neutralization operation removes the correlations across features. It’s not clear to me which one you actually want and I could see arguments both ways. Very curious to hear your guys’ thoughts!
This is a really good observation. And the answer is that the new feature-neutral idea is what we “want”.
Originally I was thinking about it as a sort of “portfolio concentration” concept, where the exposure metric makes sense. I think what we’ll likely do is change that metric to instead show feature-neutral validation score (or maybe just keep both).
If I am not mistaken, the square root of the sum of the squares of the correlations would work as a feature exposure metric that does not have that problem.
A slightly cooler metric would be the square root of the mean of the squares of the feature correlations because it has a maximum value of one and then it is equal in standing to the target correlation itself (in losses).
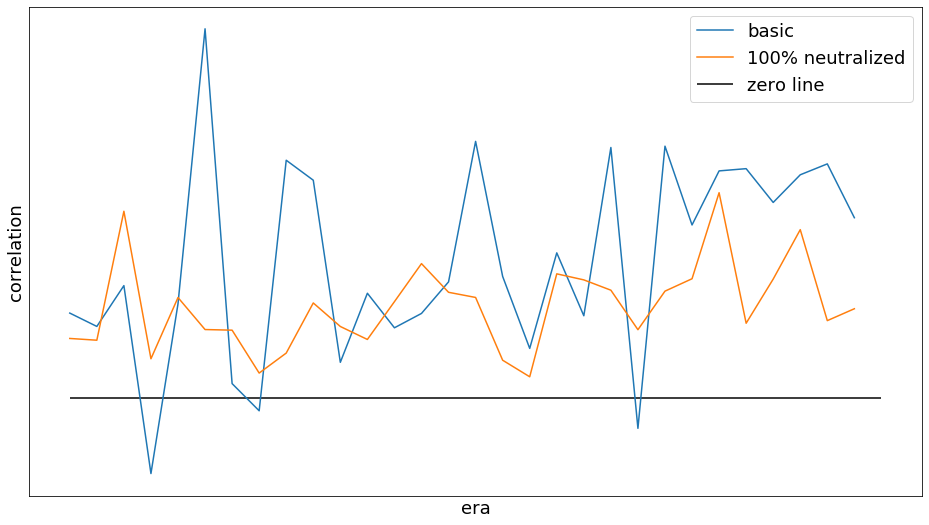
This is definitely not a strong evidence that “deeper features are necessarily more robust”, but in my case complete removing of linear feature factors make predictions much more stable in terms of higher sharp and no negative correlations across the all testing eras (see the attached Figure)
What is the metric you are using to determine the feature neutralization? Standard deviation, norm of the feature correlation vector (see above), or something else? It would be interesting to know the values of each of those metrics for both curves.
I just want to clarify that I did not used any feature neutral targets for the model training. All I’ve done - my standard training using standard targets (base model). And after that I used normalize_and_neutralize from the analysis_and_tips with proportion=1.0 for my predictions grouped by era (that is what I call 100% neutralized).
To be sure that I got your question I’m attaching code for feature correlation calculation.
corr_list1 = []
for feature in feature_columns:
corr_list1.append(numpy.corrcoef(df_base[feature], df_base["prediction_kazutsugi"])[0,1])
corr_series1 = pandas.Series(corr_list1, index=feature_columns)
print('base model', np.std(corr_series1), np.sqrt(np.mean(np.power(corr_series1, 2))))
corr_list2 = []
for feature in feature_columns:
corr_list2.append(numpy.corrcoef(df_neutralized[feature], df_neutralized["prediction_kazutsugi"])[0,1])
corr_series2 = pandas.Series(corr_list2, index=feature_columns)
print('neutralized model', np.std(corr_series2), np.sqrt(np.mean(np.power(corr_series2, 2))))
base model 0.06892674709919062 0.07109065523194119
neutralized model 0.00032925807334664204 0.00617411917434977
I like the idea of payments based on MMC values and it can really diversify the pool of submissions and increase metamodel performance. But current implementation can have actually the opposite effect. There are basically two type of models which can get high MMC: highly correlated with metamodel and with higher performance, and weakly correlated with metamodel but with lower perfromance. The former one can really utilize assumption that “Due to the increased stability (lower volatility/risk) of MMC, multiplying profits/losses by 2 brings the risk/reward in-line with the primary tournament for the average user”. However, the latter one may have higher volatility of MMC. For example, models which have less dropdowns and higher sharpe than metamodel with same average correlation probably will get average MMC close to 0 with crazy volatility (high positive MMC during bad times for metamodel and high negative MMC during good time). But from the logical point of view, these type of models are better than metamodel itself (Who doesn’t want to increase Sharpe for no cost of correlation). Old payout system based on correlation also didn’t encorage that kind of models, but at least didn’t worse (You just the the same payout at the end but with smooth payout curve). So, I’m worrying that if correlation based payout will be turned off it hurts the metamodel.
And even more, there should be some both sharpe and correlation considered in the payout as the second option, opposite to MMC based payout. But probably, if the correlation sharpe will somehow be involved in MMC calculation rather than just correlation, that can be enough to keep only one payout option.
As you @jackerparker, I have some concerns regarding MMC.
If we have a model that constantly beats the metamodel, there is probably no real need to have a metamodel… What I would expect from a model with good MMC is that it performs significantly better than the metamodel during periods where it is difficult to get good predictions from the dataset, and performs well but less well than the metamodel during easy periods.
The problem here is that integration_test performs very well overall, so these easy periods probably happen very often. Therefore the reward of such a model is probably relatively low when using MMC.
I believe it would make sense to be rewarded more during difficult periods. If we apply a reasonable coefficient to MMC during difficult eras, it should still be quite difficult to game, no? I haven’t checked, but let’s suppose that 60% of live eras are easy ones and 40% difficult ones. If we apply a coefficient of 1.5 to difficult eras, a 1-p model wouldn’t make any money (it is a bit simplified, it has to be checked in details, but in that example, with a lower coefficient such as 1.3 we would probably be on the safe side).
What do you think?
Just a side note: I think that at the moment, thanks to the new data, it will be possible for a few weeks
(or even months) to get a MMC that outperforms the metamodel very often. But it will probably only last until everybody update their models.
@v1nc3n7 Thanks for raising this topic on the chat! The only concern I have about your proposal - it requires definition of “hard times” and an additional empirical coefficient, what makes MMC calculation and prediction more complicated. On the other hand using Sharpe (or Sortino) will also help in the issue you described and it is more simple to implement and to analyse
@jackerparker “hard times” can be defined very easily, for example it could simply be when the metamodel has a negative correlation. A reasonable coefficient could be defined by choosing a period of time (typically 20 eras, but could be different), and checking what is the ratio of positive eras over negative eras for integration_test during this period of time (we could take the average or something different). That wouldn’t really make the computation of MMC more complicated, it would be just multiplying the result by a coefficient. And anyway, we cannot even compute MMC by ourselves, only Numerai can, that would be very easy for them to implement.
The big advantage of Sharpe or Sortino compared to MMC is that indeed it is a measure we can compute ourselves, so it is easier to analyse. The disadvantage is that like with the current bonus, it requires the users to not miss any submission for a long period of time. It is particularly not friendly for new users. Furthermore we could expect the metamodel to have already a very high Sharpe ratio that would be very difficult to beat.
I think the idea behind MMC is that they want us to be able to provide models that improve the metamodel during tricky eras, even if our model is just average on the remaining eras (our model shouldn’t be bad either, else it would be too easy to reach this result). Since Numerai is combining a big number of models, they probably don’t particularly need that our models perform very well all the time.
hi @jackerparker not sure I totally understand but here’s my feeling on MMC.
if a user submits a model that’s strongly correlated with the meta model but better then they get MMC and that’s a good thing.
if a user submits a model that’s weakly correlated with the meta model but still has performance that’s a good thing as well. If the meta model has an expected return of 0.03, and a new perfectly uncorrelated model has an expected return of 0.01, Numerai definitely wants that 0.01 model to be submitted even if its high volatility because it will be very additive to the meta model and improve it’s Sharpe.
Hi @richai. I would like to explain my concerns one more time in more clear way. I got your points and I’m completely agree with that. But my concern about another type of situations: When a user’s model contribute in increasing of metamodel’s sharpe. The most extreme example if a user submit a model that’s strongly correlated with the metamodel, have the same expected return of correlations, but has a much better Sharpe at the same time.
What do we have in the results:
In old payout system, the user will be ok. He will get the same payout as the person who submits metamodel ( ), but payment will be less volatile due to higher sharpe for the first user and everyone happy here. In the new MMC system, the higher sharpe model user submits - the more volatile payment will be. That is what I really don’t like here. If someone works on MMC-profitable models, he has to keep sharpe as much close to metamodel as he can. Even in not such extreme cases, when someone developed model low-correlated with metamodel - his MMC payment probably will be more volatile for model with higher sharpe even the rest of performance metrics will be exactly the same.
And I don’t argue here about the topic - should more stable models get higher payout than less stable models (however it is also important question). My main point here - more stable models should get more stable payout as it was in correlation-based payout system. Current MMC payment system just do the opposite thing.
Another way to think of the same problem is to see the rounds as being a mixture of “easy linear-signal round” and “difficult round”. The model that does decently in both types of rounds get penalised by the MMC2 scoring algorithm each time we are in an “easy linear round” (of which there are quite some), because the models that do well in both regimes get outcompeted by those that are right only in the easy rounds.
My “solution + unthought of flaws :-)” is for Numerai to split their test set into two, sampling 20 random eras each round from the part of the test set that they are going to leak a tiny bit of data from (keeping the other half pure), and scoring MMC in some way (sharpe? smart sharpe?) on those 20 random eras + live eras.
Numerai might need to ensure that people aren’t using multiple models to generate the test results that they submit, based on some knowledge of when what test era happened and how linear models performed then - for purpose of submitting, all test eras could just become one giant era - we don’t need to have that data split up in eras.
TLDR. The current metamodel appears to promote strategies that are similar but slightly better than the metamodel.
Regarding “if a user submit a model that’s strongly correlated with the metamodel, have the same expected return of correlations, but has a much better Sharpe at the same time”. The model as graphed is basically a no-risk near-flat line. If you had such a model (basically impossible, especially if the metamodel was really was going up and down like that), then why would you even be thinking about MMC? The MMC payout will be optional (and according to MikeP must remain optional for game-theoretic reasons), and so if you had a model like that you’d just leave it on the normal payout system and you’d do fine. With compounding, you could retire on such a model.
MMC doesn’t have to be all things to all people – I don’t think it is a problem that some models just aren’t going to do well under MMC scheme since you aren’t forced into it (especially if they do well under normal scheme). So the question isn’t really can we think of scenarios where MMC payment is going to be worse than regular payment – yes of course we can, so if we have a model like that (and can tell it is a model like that), we simply wouldn’t opt for MMC payouts.
But you are getting to something here that I think is interesting, in that what a “stable” model is (in terms of getting high scores and stable payouts) is going to be different depending on which payout system you are opting for. So we know what a main score stable model looks like – it is right in an absolute way about the same amount most of the time (sometimes at a high level compared to metamodel, sometimes lower – like in your upper graph). Whereas an MMC stable model (in terms of getting around the same MMC score most rounds) will probably have main scores that are all over the place and the idea is to always be adding value to the meta model. And that may turn out to be an easier proposition. This does NOT mean it has to be “better” than the metamodel (on average), I think it is misleading when people say that. Probably nobody will be better than the metamodel over time – my guess is that it will be impossible to achieve that (as long as we have a sufficient user base submitting many models). The idea is not to have a model be better than the metamodel (which of course includes that same model), but that the metamodel becomes better with your model in it vs without it.

 ), but payment will be less volatile due to higher sharpe for the first user and everyone happy here. In the new MMC system, the higher sharpe model user submits - the more volatile payment will be. That is what I really don’t like here. If someone works on MMC-profitable models, he has to keep sharpe as much close to metamodel as he can. Even in not such extreme cases, when someone developed model low-correlated with metamodel - his MMC payment probably will be more volatile for model with higher sharpe even the rest of performance metrics will be exactly the same.
), but payment will be less volatile due to higher sharpe for the first user and everyone happy here. In the new MMC system, the higher sharpe model user submits - the more volatile payment will be. That is what I really don’t like here. If someone works on MMC-profitable models, he has to keep sharpe as much close to metamodel as he can. Even in not such extreme cases, when someone developed model low-correlated with metamodel - his MMC payment probably will be more volatile for model with higher sharpe even the rest of performance metrics will be exactly the same.