The historical Numerai Meta Model data is such a great addition, well done. Also the 20 additional models per user are very welcome as well, especially now with all the new possibilities to test. If only you could deploy the account level staking feature too, then I would be happy to start trying new experiments again.
2 Likes
Randomly missing data is a really bad practice. There is no good way of dealing with it.
Randomly missing data is the rule rather than the exception with real-world data. There are certainly ways of dealing with it. And it is missing for everybody here so you’re at no disadvantage.
5 Likes
I meant there is no satisfactory way of dealing with it conceptually, except ad-hoc hackery.
On the technical side, if I am converting .parquet to .csv, how are these missing items going to show up? Will there be space between two commas , , in its place, or will all the following features in a row be shifted up and then missing at the end? Would you consider at least introducing a marker, such as ,2.0, (= missing item) , by which they can be recognized?
Ad-hoc hackery is underrated. And although you can’t really deal with questions of why something is missing in an obfuscated dataset, you can deal with it in a conceptually coherent way just treating it as “thing you must deal with that everybody else also has to deal with” and think about what is the best way that is going to work for your methods?
They’d show up as NaNs or NAs I believe but there may be settings somewhere to control that (in your import/parquet function) – we already have rows with some of the targets sometimes missing in v4 – same as those I woud think.
1 Like
Could you please explain how you arrived at 1586 features?
Under 4.0 we had 1191 + 405 new ones = 1596
There were 10 “dangerous” features removed from the data set.
2 Likes
Hi master_key,
Could you please elaborate on the meaning of:
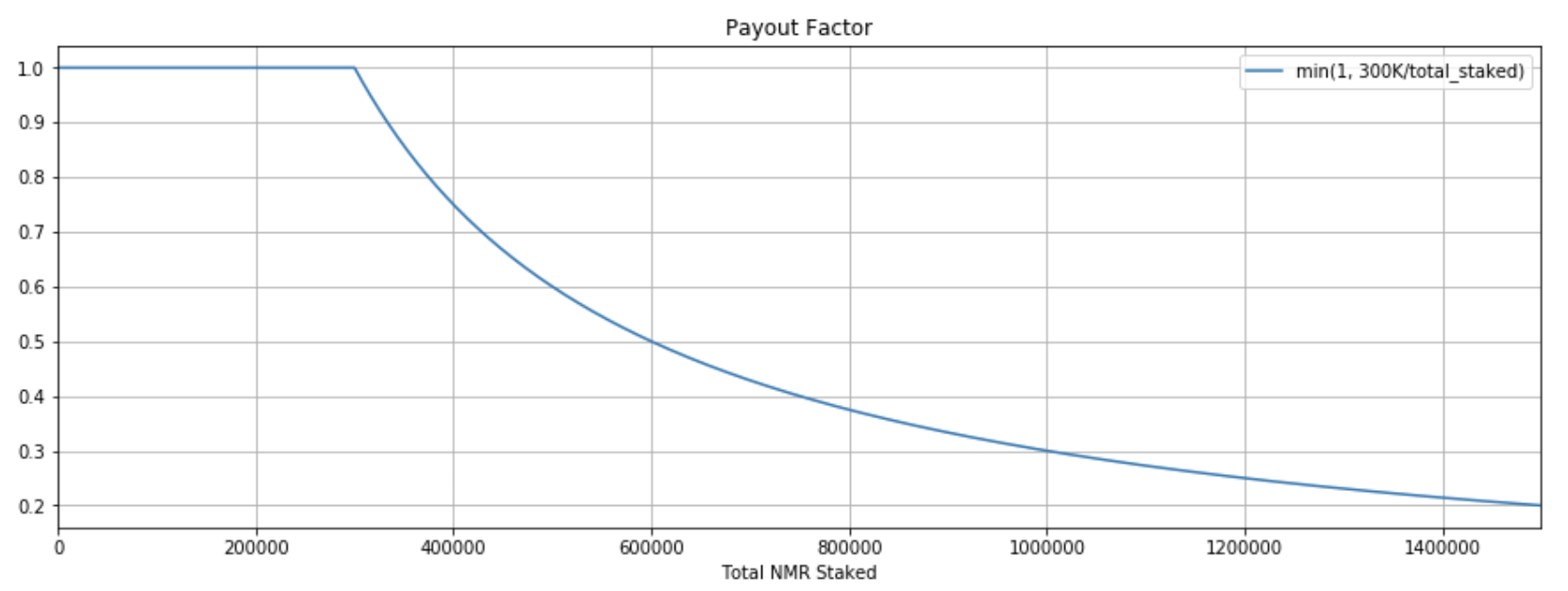
We’ve also raised the staking threshold by 20% for the Numerai Tournament, from 300k to 360k.
Is that when the exponential decay for payout factor starts? or what is the new threshold for?
Thanks!
1 Like
Does the validation dataset now contain the daily eras? If yes how can we identify them? Round numbers and era numbers don’t match. It would be misleading to train or validate on dataset that has weekly cadence for most of it and daily cadence for the last part. This would scew the model towards towards the very end of it
Love the addition of meta_model prediction results! Regarding these; currently the meta_model.parquet consists of eras 0888-1038. Assuming Numerai continues to update this parquet file with new eras as they become available, is there a plan to back fill eras earlier than 0888? Is that even possible with nomi?
The Diagnostics eras start at 0857. I think it would at least make some sense to include all the eras from the diagnostics set, if possible
No all of the data is still only weekly
Not really possible to include older meta models just due to system changes prior to the first era chosen
You can see some more detail here: Numerai Tournament Overview - Numerai Tournament
The gist is that once there is more than 300k staked across all users, everyone’s payouts are multiplied by 300k / total_stake .
But that 300k is being changed to 360k now.
It’s great that the historical meta model predictions have been released. I’m wondering what the correct way to calculate TC of my models based on his is though. Any pointers?
Just in case, should we expect NAs to appear in tournament data as well, or are they only in the historical data? Thank you!
2 Likes
Hi, I have a question, It is not clear to how to ‘Build a new target by neutralizing an existing target to the Meta Model’. You only can neutralize a prediction (or target) but not one out of the other right?
Basically subtracting the metamodel from one of the given targets, and training on the residuals. (You can only do this eras >= 888 where we have the metamodel predictions.) And then if the future metamodel is like the old metamodel, and the new eras are like the old eras, then the mistakes it makes going forward should be similar and your model will pick up the slack. The first assumption is not bad – the metamodel seems to change slowly. However it may not stay that way precisely because people can now make models in this way. The second assumption is more dubious but we have that problem of non-stationarity of the market no matter what strategy we use.
2 Likes
Am I missing something?
Where does the number total of features 1586 come from, 1050(v4)+405(v4.1)=1455 and where are the other 131 features?
1050 was v3. v4 had 141 more = 1191. But then 10 were designated “bad” from v3 & v4, and those were gotten rid of for v4.1. So 1181 v4 features carried over to v4.1 + 405 more = 1586.
4 Likes
Is the gap between the last era with targets in the validation data and the live era known ? constant ?