oh haha I see, appropriately trademarked
1 Like
nice, interesting to see how this developed.
I haven’t fully replicated all my modelling methods on the new dataset yet - with the newer data update coming, probably I will do more after December.
Nevertheless, after a few tough rounds, most of the legacy models seem to have recovered - some of them never suffered in the first place - so I am just happy seeing them running. I would definitely keep most of my new models at least for 20 rounds to see how they play out longer terms 
I think a possibly underrated subject of the new data is all the new targets. I think they’ve been maybe more helpful to me than the new data itself.
5 Likes
Do you have the cumulative scores plotted? I can’t make much out of these plots.
My experience is that my legacy workflow has beat a similar workflow on the new data. I don’t have all the comparison data together to show, but yesterday my legacy model returned 4.8% and was 95 percentile on corr and mmc. My co-modeler burned -0.4% and was 40 percentile on corr and mmc. I’m not excited about being forced down the new data route.
No not yet, good idea though, I will add that when I come to further work in my dashboard
Yes that is one of my observations at the moment, from my point of view seems some of the new targets are more volatile than Nomi
Not sure how much they help though, probably need a longer runway to see. For now my legacy models are out performing the new ones simply by being more stable
It is my recent rounds observation too, although I think more rounds are needed to draw any conclusions.
I don’t like being pushed to use new dataset neither. Have you tried to 300+ features they said are closely related to the legacy features?
I have not tried only using those. I didn’t realize that there was a list of features that were “closely related” to legacy features. I remember the question being asked about which features are the old features and the answer being that none are the same because of the timing differences. Is that list published or maybe I just missed it in the original announcement?
Needs fact checking but from memory the tournament 3 month avg was around 15-20% when the new data came out and is now at 7.7%. I was around 25% when it came out and now I’m at 49%. I’m assuming that the meta model is currently dominated by models on the new data set, while I have been playing it safe and sticking with my legacy model while I see how the new data performs.
Green is staked legacy, Orange is unstaked legacy experiments, Cyan is unstaked super massive.
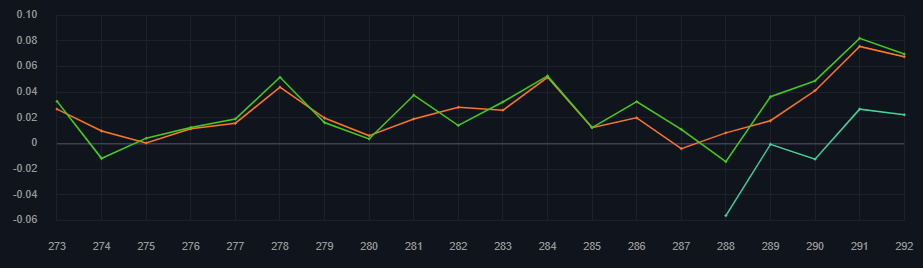
2 Likes
from the team’s October Updates
under New Feature Metadata - the “legacy” set
Legacy: 304 of the original 310 features that were carried over to the new dataset. You can use this set to achieve nearly the same model as the legacy data.
1 Like
Are we to assume that it is the first 304 features?
I remember that post. It doesn’t help though if I understood your suggestion correctly since they won’t tell us which ones are the 304 to be isolated.
The JSON file tells you which 304 features are the old “legacy” features. You should read this again: October 2021 Updates
2 Likes
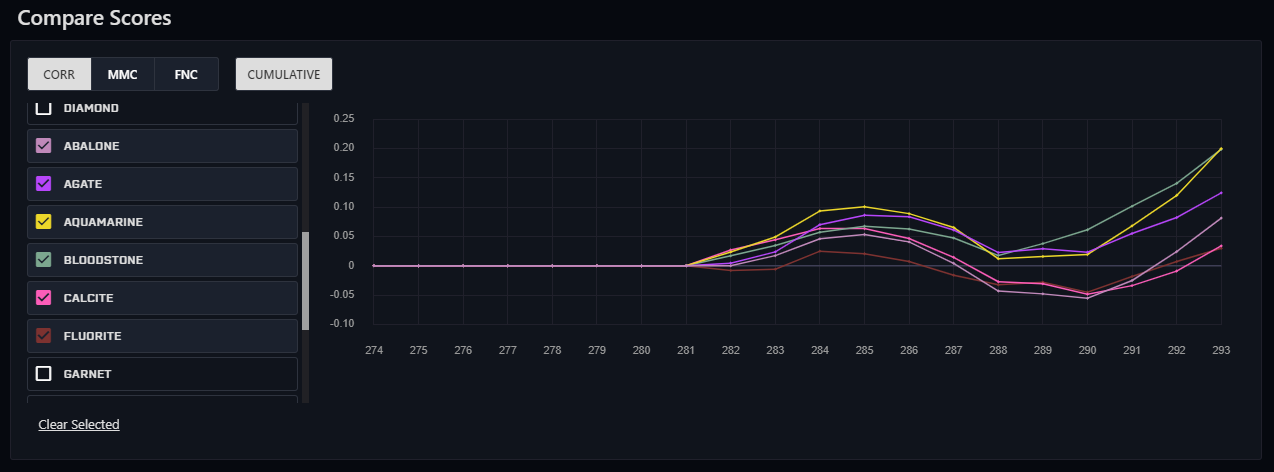
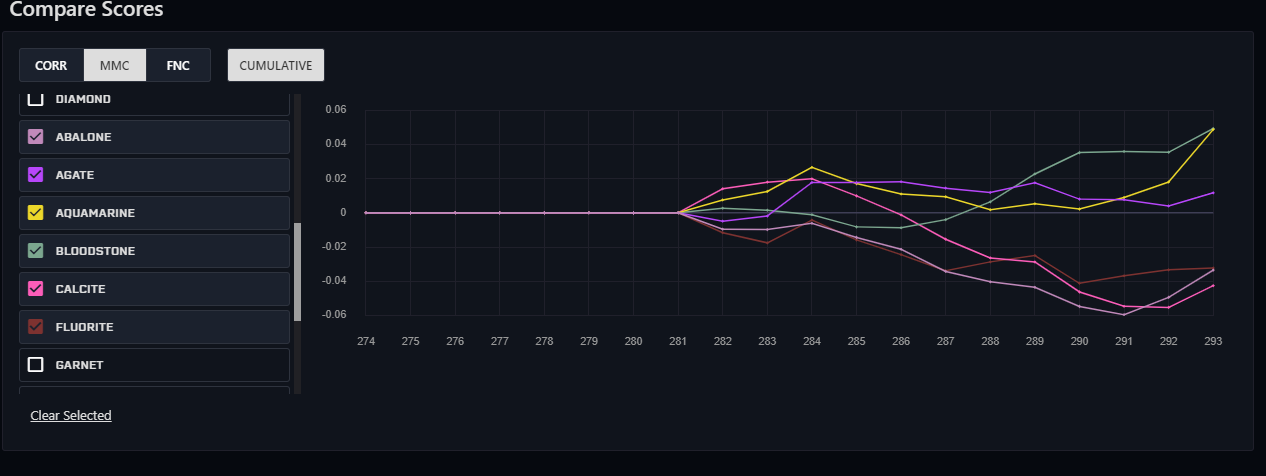
Looks like two of my models on new data seem OK but can be better. The best ones so far for me are low to almost 0 proportion feature neutralized models. MMC not so hot.
1 Like
I have tried to loaded two versions of examples weekly, legacy vs mass , legacy performance is better.
Thanks, I missed that communication.
It seems that some new targets are indeed better for live data. I will still wait 3-4 more weeks, then change to either a single model or an ensemble model on the new data.
How hard is the new data validation set? If I apply my old pipeline from the old dataset I get model with these stats on the new validation dataset: corr 0.01 sharpe 0.4; however, the same model trained on the old dataset manages to do 2.5x better on both stats on the old validation dataset. Is the new validation dataset significantly harder or is my pipeline not easily transferable? Do you have same experience?