One key aspect has been overlooked so far, even tough it seems obvious and @richai even talked about it briefly during Numercon. He said, that a models correlation with the metamodel should be below 0.5, if we we want a significant contribution from it.
TC is kind of a measure of uniqueness. So is the correlation with the metamodel. The above mentioned posts ignore this simple metric, even though it seems meaningful.
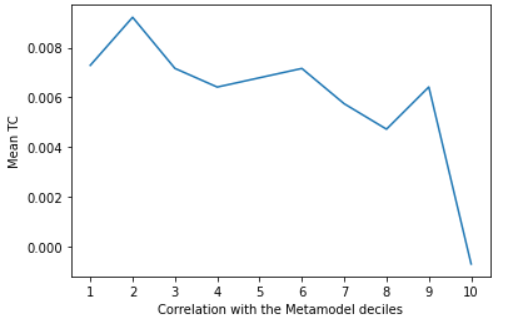
I’ve downloaded the closed round details for all staked models from round 300 and looked at the correlations.
As expected we get negative correlation between TC and corrWMetamodel. While the correlation of TC and corrWMetamodel is lower than that of other metrics, it’s still significant.
Here I plot the mean TC agains the deciles of metamodel correlation.
Hello, thanks for the nice plots. I am not too surprised by these, as 100% correlation with the meta model also means most of the stake is already on this kind of prediction = low TC.
I have one problem though, as your post title mentions “optimize” for TC. For trying to optimize for TC by optimizing not being correlated with the meta model, you need the actual meta model predictions, which is something that i really wish would come with the train/test parquet files as an additional column.
Without these, it is again less “optimization” and more “cooking”, meaning you try out anything and stick with what (seemingly) works.
Here are corr w/meta model bins in case anyone else is interested:
[-1,
0.4285466351580885,
0.5349795884635565,
0.6019820548100896,
0.6484948268044857,
0.691438100728163,
0.7332765115467375,
0.7667744838998147,
0.8015134126302096,
0.8459169152554307,
1]
I agree. I am currently using example prediction instead of metamodel prediction to improve TC.
Because example has high corr with metamodel.
If metamodel prediction is published, I think it would be very useful to improve TC.
Is there any problem with making it public?
You can approximate the MM with the example prediction and train your model to be differrent.
Or, you can wait until the next Friday, where you get the exact figure on the MM correlation.
MM correlation doesn’t change a lot over time, so seeing one can be enough. It’s still a lot faster feedback loop than waiting months for TC.
Unfortunately there isn’t much data in the low correlation range. Even though having low or even negative correlation could be very useful and profitable.
I think it would only be a “problem” if the tournament would comprise of 1 very large staked model. In this case their predictions would be “leaked”. In the current tournament i dont see a problem with it.
I think you’ll see corr tracking the same way. Some periods are just easier. (In other words, I don’t think any great discovery was made around 322 or the staking got any smarter – just normal ups & downs.) A rough difficulty score for each round can be had simply by looking at the percentage of all models that are positive vs negative for corr or tc for that round. When judging my own models I want them to be doing relatively well both in easy & hard rounds.
(DATA PRIOR TO R311 is not valid. Method mistakenly used models staking on MMC as using TC)
Only since R308 has the corr of TC staked models started to underperform the corr of Corr only models. Perhaps that is a sign of TC models turning up their focus and efficacy on TC.
@greyone TC staking only started since round 311. Also, how do you define a “TC staked model”? Do you take into account the change of their multipliers each round?
Yeah, there is some TC backfill there where no one was actually staking on TC. But yes also in all my newer TC-focused stuff I’ve just dropped even looking at corr – they are quite weak on corr.
@restrading thanks for catching that error. Method defined TC models by using the minimum absolute difference between actual NMR payout and the calculated options at 1C, 1C.5TC, 1C1TC, 1C2TC and 1C3TC. If min was 1C then that model was labeled Corr only. All others were labeled TC. Ergo, the data before Round 311 is in error because method assumes models betting on MMC were using TC. So discard all preR311 info. Appreciate you pointing the error.
My work often exemplifies the adage “one must be willing to be a fool before you can become wise”.
How high is the example pred corr with meta model? I think statistically 90% correlated is probably sufficient to meaningfully proxy meta model but I am guessing based on rule of thumb
They said in today’s fireside that this is coming. (Historical meta-model predictions and probably also the ability to get historical TC estimates based on same.) Eventually we’ll get it…