This year has been abysmal for my stakes at Numerai, from a high of about 10K NMR to currently about 6.5K NMR ( rounds 429 and 434 were especially dire with 1.2K in loses), all in I am about a net 200 NMR down for the year which is not terrible I guess but as I am currently in the 3rd spot by TC something simply doesn’t add up ( If you hate suspense I shot myself but there’s a case to be made that Numerai is tossing around loaded guns with the safety off).
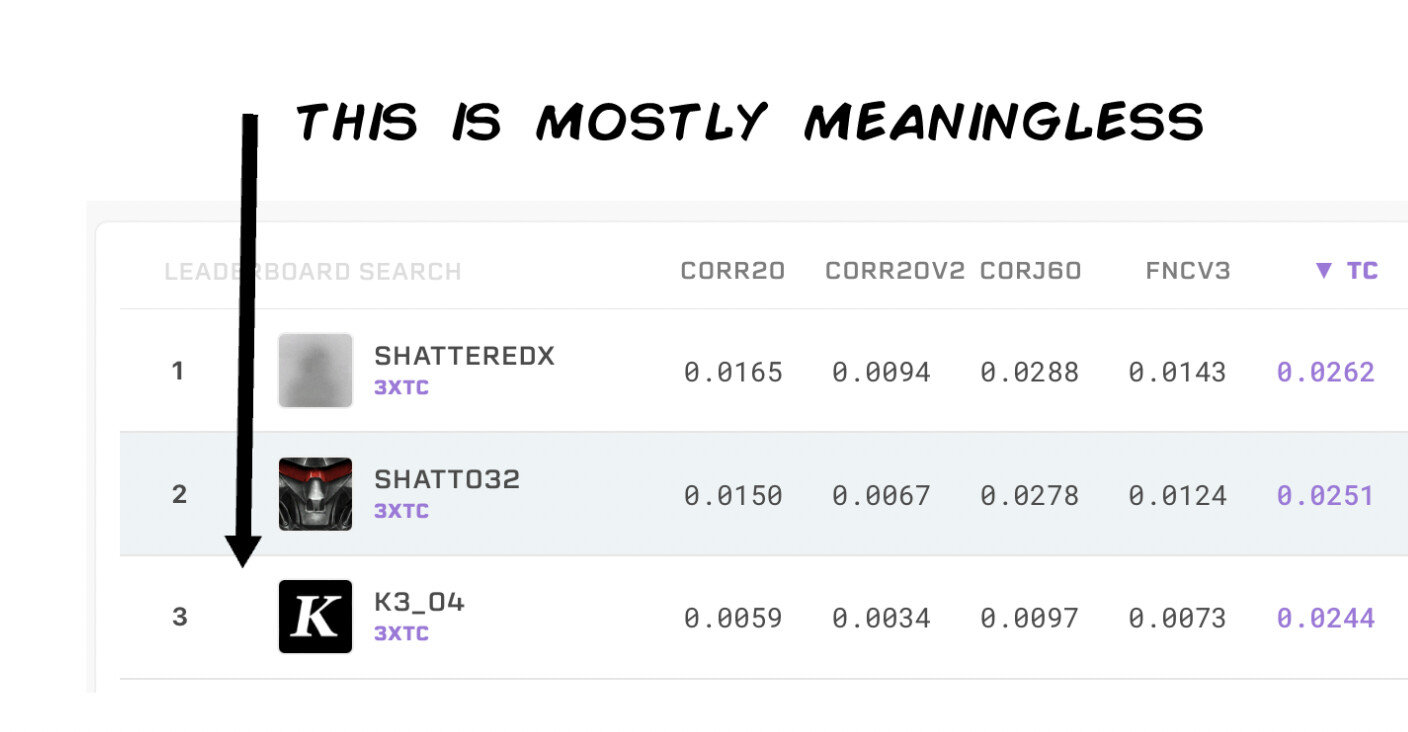
Diagnostics ? After 3 years I’ve mostly given up on asking for help to the Numerai team as they either don’t care, can’t help or don’t know how to, but the end result I think is that we have superfluous metrics that misguide us, constant changes that make tracking performance difficult and a messianic obsession with more data as the sole thing that will evolve the competition and generate the market neutral results the fund needs, which based by the latest and upcoming results might not be playing out, all this simply because we can’t efficiently allocate our stakes ( more on this later).
So why not simply quit the competition ? And believe me I think about rage quitting very often, but unless Bridgewater or Black rock comes knocking on my door, there is a better alternative ( CrunchDAO imho was not worth the effort vs $) or I can make my own fund, Numerai is still the only player so far, I also think most early competitors are waiting for another crypto/market cycle or 2 to cash out.
So why share this ? In short, our performance as a group is terrible at a time when the fund is trying to get more AUM ( probably not a good look )and since they can’t help we either get better on our own or the project dies/languishes along with whatever value you have invested/earned, tokenomics are simply not working, so more burns will not necessarily generate a higher price to pare down your loses.
So what to do about this ? Before moving on I’d like to share my findings which gave me an upset stomach yesterday, these are simple payout “backtests” on my 5 current models for resolved rounds starting at round 474 ( daily rounds ) :

There’s a few simplifications and assumptions, but the end result is that my model k3_02 would have generated the biggest return ( with multis TC 3x and Corr 1x ) while the worst would have been k3_04 ( with 3x Corr ), only one model was staked in the period and you guessed it, it was the worst possible payout combination, so why did I stake so much on the worst strategy/model ?
Greed and misdirection ?, If I run the same backtest from the start of the year (R 369 to daily starts ) I get :

The allure of higher TC was my undoing, but there was also not much in the way of risk metrics provided, TC on the leaderboard is 1 Yr which doesn’t make sense when within a 20 day period you can now blow most of your stake and gives you a false sense of security, changing data and targets also muddle this picture and the diagnostics are more of an afterthought, they should be provided automatically and be front and center, the payout scheme also aggravates the issue of chasing high TC.
The problem with rebalancing. Stakes and models.
So after this backtest the obvious measure would be to rebalance stakes to models periodically, something that is still not easily done, In my case I need to re upload/overwrite the models in compute and keep a log somewhere with model specifics and mapping through time, hardly ideal but I can’t do anything about it, I might even end up removing my stakes and have to wait 20 days… but more importantly is the issue of how predictive are these backtests and the sad reality is that after 3+ years of rounds we don’t have enough data as the change to daily and other ( and upcoming ) changes effectively were a reset of the competition, and to monitor the drift you need to run tests on unresolved rounds which are very volatile, here’s my current one for instance, rounds tend to “improve” with time but this is not a hard metric :

And these tests are just the start, I hope that with enough rounds one can start using correlation between backtests and future performance to increase predictability.
Are you running backtests ?
And lastly here’s the basic script so you can run your own backtests if you aren’t already doing so ( please do check the logic as it is not trivial ) :
Colab notebook for Payout Backtests
import pandas as pd
from numerapi import NumerAPI
import numpy as np
api = NumerAPI()
def simulate_payout(model_name, start_round, end_round):
stake = 10000
payout_factor = 0.10
max_payout_burn = 0.05
corr_multipliers = [0.0, 0.5, 1.0]
tc_multipliers = [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0]
model_performances = api.round_model_performances(model_name)
model_performances = [performance for performance in model_performances if start_round <= performance['roundNumber'] <= end_round]
payout_data = {}
for performance in model_performances:
round_num = performance['roundNumber']
corr = performance['corr']
tc = performance['tc']
for corr_mult in corr_multipliers:
for tc_mult in tc_multipliers:
if tc_mult == 0.0 and corr_mult == 0.0:
continue # Skip the combination of 0x TC and 0x Corr
payout = stake * np.clip(payout_factor * (corr * corr_mult + tc * tc_mult), -max_payout_burn, max_payout_burn)
key = f"TC {tc_mult} - CORR {corr_mult}"
if key not in payout_data:
payout_data[key] = {}
payout_data[key][round_num] = payout
df = pd.DataFrame.from_dict(payout_data, orient='columns')
df.index.name = 'Round'
total_payout = df.sum().sum()
df.loc['Total'] = pd.Series(df.sum(), name='Total')
# Rank total payouts by multiplier in descending order
rankings = df.loc['Total'].sort_values(ascending=False)
return rankings
# Example usage
model_name = "k3_01"
start_round = 474 # Start Daily
end_round = 502
# start_round = 369 #Start Year
# end_round = 474
rankings = simulate_payout(model_name, start_round, end_round)
print( model_name)
print(rankings)
print('///////////////////////////// \n')
model_name = "k3_02"
rankings = simulate_payout(model_name, start_round, end_round)
print( model_name)
print(rankings)
print('///////////////////////////// \n')
model_name = "k3_03"
rankings = simulate_payout(model_name, start_round, end_round)
print( model_name)
print(rankings)
print('///////////////////////////// \n')
model_name = "k3_04"
rankings = simulate_payout(model_name, start_round, end_round)
print( model_name)
print(rankings)
print('///////////////////////////// \n')
model_name = "k3_05"
rankings = simulate_payout(model_name, start_round, end_round)
print( model_name)
print(rankings)
print('///////////////////////////// \n')
- K
