I wanted to share an article I found recently.
It’s a simple and elegant solution for automated feature engineering.
In my experiemnts it easily pushes the CORR on validation above 0.03, which is pretty good.
I don’t have evidence yet, how it performs in forward testing, but it’s promising!
Here it goes:
The concept can easily be applied to the tournament dataset.
The key concept is on this diagram:
Out of interest were/are any of our neural net modellers also using feature embeddings and have they found usefulness with it already? I thought was only NLP focused but perhaps not.
The previous article by the same author was interesting too for feature engineers
From a NN perspective this is a bit surprising. One benefit of using NN is to learn cross feature relationships (non-linear ones). Here the author is forcing the network to learn some relationships before injecting that knowledge into a bigger network, which begs the question why not work with a big network in the first place? (such as a wide&deep architecture)
I am not familiar with the dataset used in the blog post to evaluate the result by myself (error rate from 37.6% down to 37.2%). I wish the author would have given additional examples.
Feature embedding can be quite effective outside NLP. I have been using it at work when working with sparse features. It goes like this: train an auto encoder to reconstruct the sparse features then use the encoder part (and set the weights to “non trainable”), now the spare features can have a dense representation. So far I have not been successful in applying this idea to the tournament.
Embedding categorical features is often a good strategy, you can have some intuition about how it works by looking at it as a sequence of: (1) associate an integer to each variable (2) one-hot encode the variable (now this can be super sparse) then (3) apply a smaller dense layer on the one-hot encoding. Which is what the author have implemented with tf.feature_column functions and the DenseFeatures input layer.
I don’t think using embedding layers makes a lot of sense for numerai tournament. Embeddings are useful when handling categorical data, sparse data, or otherwise one hot encoded data. If you are dealing with intervall-scaled data, there is not really a need for that and most higher-order interactions will be learned by the model itself. The embedding layer helps most when you want to reduce the dimensionality of a really big matrix. For the tournament I don’nt see the need for that.
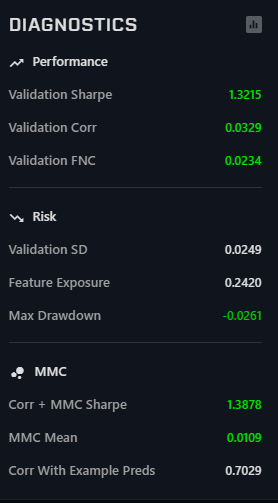
Here it comes. The highest validation corr I’ve seen so far.
The above mentioned architecture with around 100 features (I don’t have enough RAM to use all of them)
Congrats ! And thanks for the article ! A few questions for achieving good results
Are you overfitting on the training data ( by how much? )
what is your fitness function ( mse, or are you using sorted differential lib to run spearman, or a mix )
batch norm/ dropouts ?
SGD batch size ( I’ve experimented with eras as minibatch, which worked better than smaller size on my case, but quickly limited by 16Gb or RAM… for fully connected layers)
Would love to hear what moved the needle for you with this architecture.
Thanks for sharing. I have been meaning to try exactly this at some point but it is a bit intensive. I have gotten similar metrics as this with a blend of NN that have some embedding ideas but nothing this complete brute force way. Live results on 9 rounds are also promising. Really going to have to get back to trying this way.
Two things you could do to get all the features involved. You can just pass through the ones you don’t embed to the final layers. Also you can cycle the groups individually like just intelligence, dexterity etc.
So for example if you just pass through constitution which is mostly shitty features and then cycle the other groups individually you probably will have a manageable number of embedding heads with all the features involved.
While neural networks are fantastic at finding non-linear patterns, even a big network will always follow the path of least resistance during training. Meaning, it will it might only find a few strong relationships during training and ignore weaker ones. Training a single neural network to find as many relationships as possible is like kicking water uphill.
The feature embeddings in the article are able to extract patterns in from the dataset that would otherwise be drown out by stronger ones more directly correlated with the targets.
@jacob_stahl possibly yes, so far with regularization I was able to achieve ok-ish results. I haven’t check all the implementation in details but it could be useful to set those small feature-networks to non-trainable when they are added to the final model, otherwise there is a risk to “erase” what they learnt during training.
That’s the approach I’m taking right now. Since the weights on the small networks are frozen, the outputs don’t change. You can through the entire dataset and cache the outputs, and use them to train other models. I will probably try replacing the big network with an XGBoost model and see what happens.
@nyuton I think you should also consider neutralising it to improve your feature exposure and validation SD. This is awesome, but that will be a kickass super-model. It might improve your drawdown as well.