catching up on the thread- i’ve noticed that some models perform well as measured by the metrics (CORR20v2, TC) but aren’t staked. are unstaked models ignored? i like that each person takes on risk when staking their models, but i also recognize that not everyone can stake NMR- i.e. staked NMR is confounded by a person’s economic circumstance. staked NMR isn’t a pure measure of confidence due to this confounding effect.
2 Likes
The stake weighting is linear, grouping models into accounts first and combining that into the metamodel shouldn’t matter, if I understand what you’re saying @thornam .
Anything differing from linear weighting (including rank, hard stake limits, log stake weighting etc) is Sybil attackable. I guess that’s why numerai didn’t want to do it.
That’s another reason why I suggested track record based limits:
Making sybil accounts with a good track record requires time and makes attackers easier to spot.
Just to illustrate how broken the current system is: the “sparse” zone consists of 15 accounts and controls 50% of the metamodel.
7 negative TC ~240kNMR and 8 positive TC ~170k
The low stake portion isn’t great either but at least you can spot some order, which is of course destroyed as soon as a whale gets in a bad mood.
Doesn’t sound like crowdsourcing to me.
1 Like
Actually, I think we suggest sort of the same thing, as I do also suggest a track record based system.
And when you say ‘track record based limits’ you mean limits to the staked amount on a given model, right? However, this I might not be a fan of since it can discourage participants whenever falling short of those limits and restricting their payoff/stake. As was the case Richard brought up at the Fireside about how Millenium had created some angry former managers by stopping the collaboration when they fell short of the limit.
Personally, I would prefer a smoother system that automatically incorporates the track record, which is why I suggested a MetaModel that was weighted based on one’s account track record. (Notice this would not affect the possible stake on a given model).
Moreover, the great thing about the current MetaModel weighting system (in theory) is that it incorporates participants’ beliefs about how good a given model is by putting more weight on models with high stakes. However, I think we can all agree that high stakes is not equal to a good model in practice, as multiple people have argued in this thread (and that I agree with).
But we still want to incorporate people’s beliefs about how good a model is into any new weighting system because it holds much information. So that is why I suggested a combination of the track record based and the stake weighted system.
Hope this makes sense, and please correct me if I’m wrong
1 Like
I meant account based limits.
If you want to modify the system away from the current linear stake weighting, you need to do it account-based, and you need to ensure that people don’t register multiple accounts (sybils).
IMO, the pressure from foul players will be lower if there is a time component included in the limits such as a multi-month track record.
Yes exactly, it would need to be account-based.
But you do not need to worry about multiple accounts if the MM weights are track record based. New accounts would have zero (or very low weights to the MM) and only gradually contribute to the MM as the account show good performance. However, they would still be able to stake as much as they want, but only gradually contribute to the MM if the account performs well
i’d propose separating meta model contribution calculation from NMR staking. NMR staking is great for making sure valid/performant models are submitted. whether or not a model is incorporated into the meta model could be solely based upon corr20v2 and tc (or any performance metric(s) developed in the future). this does deviate from the white paper conception of the auction, so maybe i’m missing something? https://numer.ai/whitepaper.pdf
1 Like
One more post, and then I’ll let the thread be for other good ideas.
To be more tangible, what I initially suggested was a two-factor system where the individual model contribution to the MM was based on an Account Weight and a Stake Weight.
E.g.
Imagine an account with a 90 percentile ranking on the account leaderboard and 3 models (Model A, B, and C). The account chooses to stake 80% of their stakes on Model A and 10% on each of Model B and C. Then the contribution to the MM from each of the models would be created something like this:
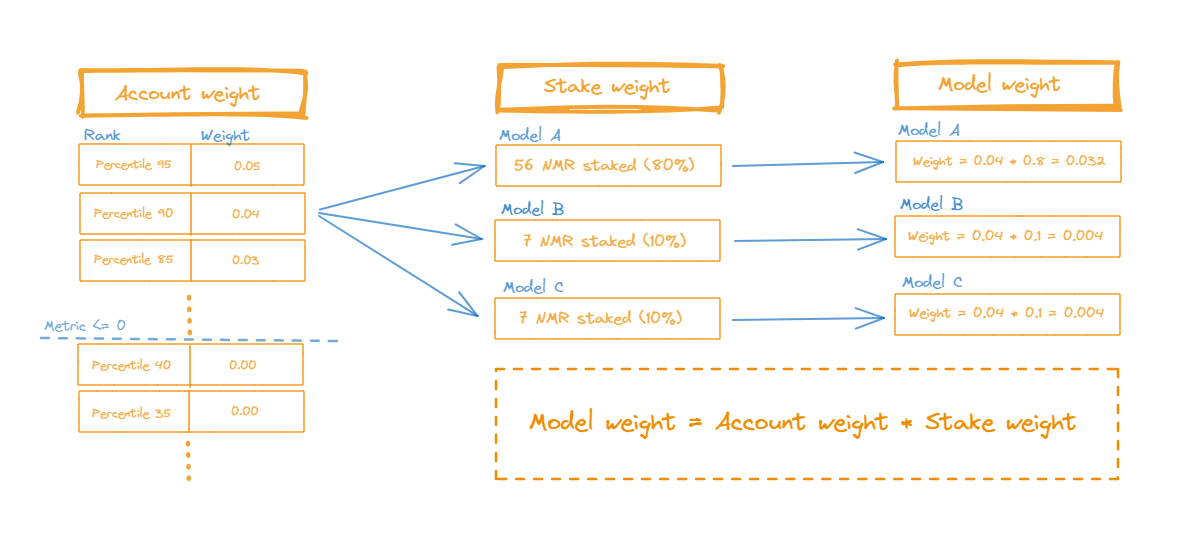
Notice that the Account weight numbers in this example are just arbitrary numbers and should be set by the fund. And that there are no stake limits.
The benefits of the Account weight are that it separates the MM contribution from the staking system (as @f58c proposes) and creates a track record based system (as @dd_dd proposes) by limiting contribution from “bad” accounts to the MM and putting more emphasis on contributions from “good” accounts. At the same time, it does not hold the multiple-account problem, since new accounts would have zero, or at least diminishing, contribution to the MM.
The benefit of the Stake weight is that it incorporates the Data Scientist’s information about his/her model. This is based on the assumption that the Data Scientist holds more information about how good or risky their model is, which is the same assumption the current stake-weighted system is based on. Thereby, a higher stake equals a better model, but without the proportionality problem between high stakes and model quality caused by differences in people’s economic situations (As @nyuton and @dd_dd argue).
Moreover, the system doesn’t limit people’s ability to stake but only limits people’s contribution to the MM. And in my opinion, it is not necessarily the fund’s job to prevent people from staking on bad models, but it is their job to prevent bad models from contributing to the MM.
This could create a system that holds multiple of the good ideas I’ve seen in this thread (separating the MM contribution from the current stake weighting, creating a track record based system) while tackling the proportionality problem, and at the same time having a flexible system that doesn’t limit peoples ability to stake on a given model, but instead limits the contribution from a given model to the MM.
3 Likes
Stake limit MUST be avoided, because that results in the liquidations of large NMR holdings, thus causing the collapse of the whole ecosystem!!!
I suggest a “personal payout factor”, where the ranking (past performance) of the account is incorporated into the payout factor as a multiplier.
New or bad performing account would get a lower PPF, thus they can lower influence on the MM and lower payouts.
Good performing accounts would get a hiher PPF, thus enabling hiher MM impact and higher payouts.
Note that, this approach doesn’t directly force participants to liquidate NMR holdings. It just limits the account’s impact and payouts.
1 Like
Payout factor black market created?
3 Likes
- The stake limit is tied to model’s TC history. (EDIT: maybe stake weighted TC should go here instead, need to think more on this)
- An auction system enables whales to compete for free stake space of each model. Bigger whales can pay more and will get the best model.
- If overstaked, the TC mechanics will gradually reduce TC/stake limit, so that the next best model becomes more attractive
That way stakes should move to better models and enable more earnings for model owners, compensating for the PF reduction caused by whales.
If the TC reduction works as advertised, then it should also automatically take care of the sybil problem, as TC would detect similar models belonging to different accounts and reduce their TC/stake space accordingly.
1 Like
Why do you guys think “track record before staking” should help in the first place?
This is the ATOL performance just before the drawdown:

If you waited those 6 months before letting them stake, you would actually end up in a much worse position, because you would miss those 6 months of profit…
3 Likes
The only reasonably good metric that let’s you judge, how good someone is: the all time returns.
Ultimately that’s what we all are optimizing for.
Even a random model can have decent TC for 6 months…
All time returns include good modeling for many eras, drawdowns included.
All time returns include years of experience, with many models.
All time returns include good risk management. Let’s face it 3xTC is rarely a good idea.
All time returns include good allocation of stake. Anyone can have a model in the top100. But putting most stake to the best future(!) performance is a skill.
1year TC doesn’t mean much.
I have two in the top100. Based on that one could say I’m one of the best.
But as a matter of fact, I haven’t earned anything with them ![]()
Look at all time returns to get a good judgement of real performance.
Good stake allocation is just as important as good modelling.
It’s somewhat unfortunate that there is no way to get a good judgement of someone faster.
Any monkey can have good one year performance.
Warren Buffet is admired for his 60+ year track record.
Noone knew his name after the first few years and not because those were bad.
4 Likes
Well, apart from models bought at Numerbay most of ATOL models are actually mine. They had a good track history before handing them to ATOL:

My account has been there since 2017 and has a return of 651%, so I would definitely have the track record anyway.
You can’t have model performance with longer history, because there is a new major dataset release each year and it is pointless or even impossible to use older datasets for anything.
So what you propose is completely unrealistic.
Also, one of the reasons for our drawdown is that we kept staking on old (but proven!) nomi-trained models and nobody told us that it was a bad idea. These models failed the most. So this example actually proves that nothing based just on past performance can actually work.
A few points to take out of this:
- Past performance is not an indicator of future performance
- Not everything is the fault of big guys
- Drawdowns happen and avoiding them just causes other drawdowns
6 Likes
@quantverse Compare your 1y plot to the top 100 accounts.
With the auction system I suggested, you would be allowed to place a slightly above average stake, maybe ~1k, but if you really want to stake more, you can bid for something from the top of the LB.
My point is not to blame a specific account, but to show that letting 15 individuals have control over 50% of the metamodel counters every principle that numerai is built on.
I’m trying to figure out sustainable ways to force whales to join the crowd or at least to get some order into the stake distribution.
2 Likes
I don’t think that it was ever meant that a model with a stake 1000 times higher than an average stake is supposed to be 1000x better. It was about the more confident you are about the model it will be good, the more you stake and therefore the more you risk. Then you should be more careful what you stake on and if your models burn, you are more incentivized to do something about it. And if you don’t, the burning stake self-corrects the meta-model by decreasing the weight.
The two biggest stakers here are funds, so they stake their client’s capital and they have the responsibility to the clients. So if they are not bringing a return to their clients for some time, they will be forced to stop staking eventually. So I would think the incentive alignment still works.
And no, this feedback loop aside is not enough to prevent drawdowns. Nothing is.
3 Likes
It won’t work, because the ranking in the leaderboard is
- often pure luck
- based on historical performance
The best model with rank #1 can be the worst in one year. Believe me, I had many models in top 50 for long time.
This account uses my models too: Numerai and it is #23 in TC. Just the stake distribution and timing made it appear better and have a better rank.
1 Like
But I guess you didn’t put all of your stake on these lucky models.
I corrected “TC history” to “stake weighted TC” in the auction proposal.
If that doesn’t work for some reason I’m currently not aware of, account performance history should work.
Claiming that history means nothing is equivalent to the claim that eventually everybody’s performance is the same. A pretty destructive argument and it’s actually not true.
Actually, we did that - we bought the top LB models and staked on them. This caused a major loss. This is a big mistake and a good example of how selecting models based on LB rank is doomed to fail.
2 Likes
But my example of my track record is stake weighted, so it would be relevant if track records were considered.
1 Like
But some others made a fortune doing the same. That’s another evidence how extreme staking and letting a few individuals control the MM only introduces noise and volatility.