Since Numerai’s hedge fund portfolio is weighted accordingly to the stake value of the models, the more they are valuable to the hedge fund the more their stakes have to increase. That enables a feedback mechanism where the most useful models are most rewarded and consequently they increase their hedge fund weight.
In the beginning all was straightforward: models were rewarded as much as their predictions were correlated to the stock market.
However the model predictions are not used “as is” in the construction of the Numerai’s hedge fund portfolio. Their predictions are subject to constraints such as maximum exposure to a single equity, maximum exposure to a single sector, maximum turnover etc.
For that reason TC was introduced, which “represents how a stake should be changed to increase overall returns of a hypothetical portfolio” and models rewarded on this metrics.
That raises a problem though: models are not rewarded for what they are trained for (the actual stock market performance), but on a derived metrics, TC, which is not trainable by the models. In other words, the models are not trained to predict what the hedge fund needs (the actual stock exposure in the portfolio). Also the users are unfairly rewarded, because they have no way to train models to maximize TC.
One solution to this problem is to drop the current data target (“stock performance ~4 weeks into the future”) and to use a new target instead: the exposure a hypothetical portfolio should have had in each stock in the last ~4 weeks to maximize whatever is the hedge fund goal, keeping into consideration all the portfolio constraints.
This change would re-align the model training target with the hedge fund requirements and the user reward.
While I somehow share your sentiment, you can at least try to optimize for FNCv3, which is a metric that can be calculated beforehand. In my experience so far, FNCv3 is the best indicator for TC, which was also stated at TC introduction.
I found my CORR and FNCV3 are good enough and started staking on TC, and then suddenly I got very bad TC. The correlation between TC and FNCv3 is not so robust.
I think its a very big “if” whether or not training on such a target would be predictive of future rounds (and the future needs of the fund). I’m not sure such a target would even be feasible to create. Seems like it would be pretty random, and training on random numbers would not help you to predict future random numbers. (i.e. the undesirable behavior of TC might be the same or worse) It kinda sounds like v1/beta of TC where the actual current portfolio was being used to determine TC (that is no longer the case – it is now generating a hypothetical portfolio from scratch without regard to their current positions).
The sticking points with the current TC are:
It isn’t a “target”. Can’t train/optimize for it directly.
You can’t validate a model TC-wise on historical data. (related to #1, but different)
It is highly volatile/inconsistent.
#1 seems to be a major complaint around here, but personally I find that one a non-issue. (I think many people want a kaggle-style thing where they are competing to see who’s best at training things on fixed data.)
But #2 & #3 are real problems. #2 could be solved by fixing #1 and creating a trainable target (maybe not possible), but #2 could be fixed independently also by some validation tool that made fairly accurate TC estimates (but might fail if you over-optimize for it). Because right now we basically can’t tell if we have good models or not. I’m not sure it is even clear if “good models” in the sense that they can earn TC and keep earning it for anything beyond the short-term are even possible. So it could certainly use some improvements or smoothing out (or a tool that allowed us to learn more about it on old data).
As I pointed out in the other thread, if TC fails as a feedback mechanism to create a positive loop, then it is a failure and they won’t fail to notice that because the metamodel will suffer (or everyone will have switched back to corr – maybe it is all just a plot to no longer pay us on MMC?).
If TC score of a model is highly volatile, then its TC reward goes up and down or its owner turn off TC multiplier.
If TC score of a model is consistent high, then its TC reward and stake amount goes up and up and up and that’s what numerai need.
Few models got consistent high TC, but there were.
Find out those models and reward them will help numerai.
We don’t know how to get consistent TC, that’s a problem.
Even if FNCv3, TB200, CORR,MMC are all high, it’s still easy to get negative TC.
Maybe we just don’t know how to adapt to the optimizer.
I believe I fail to properly explain my idea of the possible solution.
The new hypothetical target I am suggesting, would be the optimal exposure/position Numerai wish they had in each stock at a specific point in time. That has to keep into considerations all the constraints the real hedge fund has (there would be multiple targets if they have multiple funds). To compute these optimal positions (i.e. the hedge fund portfolio) Numerai has to make use of the current target (“stock performance ~4 weeks into the future”) but that is not given to the users.
if we trained our models on this new target, the models would learn how to build an optimal portfolio given the stock features. That would be like integrating stock prediction and portfolio optimization in a single model.
The benefit of this new target would be that the models could be rewarded on the pure correlation between their predictions and the portfolio Numerai wish they had at that particular round knowing the actual stock market performance at round end. That optimal portfolio used to compute the correlation against our model would be the target in the training data.
Feels like building the type of model that minimizes TC score …
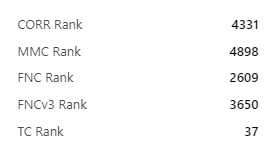
For me TC is super random and I’m still not sure what to do.
Optimizing on CORR, MMC, FNC, FNCv3 isn’t working for me
Feels like building the type of model that minimizes TC score …
For me TC is super random and I’m still not sure what to do.
Optimizing on CORR, MMC, FNC, FNCv3 isn’t working for me
We have actually tried to make targets that work much like that, but haven’t released them because they don’t actually work very well to train on as they are very sparse. However, we are about to revisit target construction and do take your feedback seriously. I could see us doing something like moving to a new correlation target that’s very similar to what you describe, but with the caveat that we really don’t recommend training on it directly, or at least in isolation. But some version of TC isn’t going away as it solves the problem of properly rewarding unique contributions.