Today we are releasing the biggest upgrade to Numerai data in over a year. It’s called Faith.
Dataset V5.1 introduces 186 new features, including some of the highest performing and unique features we’ve ever released.
A standard example model using the parameters found here: Models | Numerai Docs, built using this new V5.1 dataset, does better than an identical model built on the V5 dataset in nearly every period.
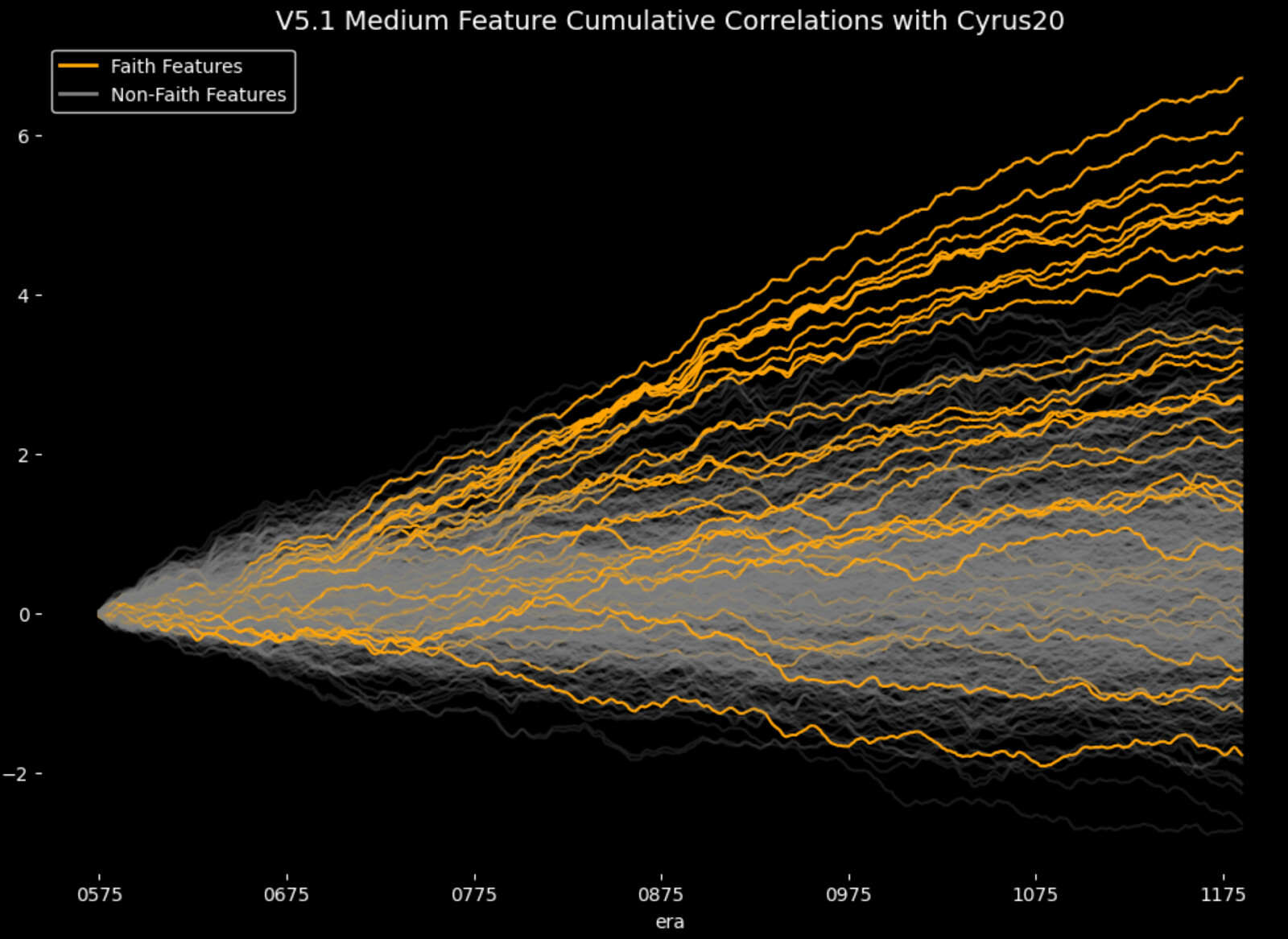
They are extremely predictive and unique. Several of the faith features are by far the most predictive, information dense features we’ve ever released.
These two facts have interesting consequences for modeling.
Since many of them are missing in earlier eras, it means that most models will not use them heavily, even though doing so would increase performance in later eras.
Some candidate ways to handle this:
Remove the first two hundred eras from training to increase the concentration of samples which have the features present.
Impute the early missing data in some clever way that maintains the expected correlation vs target and correlation vs other features.
Ensemble the best but sparsest features with your models’ final predictions in order to upweight those features and compensate for their early sparsity
Here is a quick demo where we
Take the 5 best faith features from the medium set
Equal weight those feature values into one super feature
Gaussianize that super feature
Blend it with the V5.1 predictions with 80% weight v5.1, 20% weight Faith super feature
v5.1 validation.parquet is 7.3 GB today versus 3.3 GB for v5.0
This will impact models that are memory-constrained (or GPU memory-constrained) during training. If a model trained on all features of v5.0 is getting close to a memory limit when training it is likely to run out of memory if attempting to train on v5.1 unless a subset of features is selected or the number of eras in the training data is reduced.
When new data is added to validation.parquet each week, the only way for participants to fetch the new data is to re-download the entire 7.3 GB file.
Has anyone considered that if the data format was CSV instead of parquet, an HTTP GET feature could allow the client to just download the new rows, saving a lot of time and network bandwidth at the numerai server.
CSV files would be extremely large and difficult to download or maintain. However, it might be useful to include an option to download Parquet files for specific eras instead.
Regarding GPU OOM issues, you can train on a subset of features and/or eras, or consider upgrading to a GPU with more VRAM. If you’re using TensorFlow or PyTorch, you can also train using data generators and mini-batches to ensure the data fits within your available VRAM.
The v5.1 validation parquet file is not 7.3 GB. It is 3.8 GB. It said 7.3 GB because it was overwriting your old validation.parquet and adding the two file sizes together. This is a known quirk with downloading new versions of parquet files with Python
Dear Kagglers, V5.1 data are now available on Kaggle platform with weekly automatic update:
numerai data is public notebook, automatically triggered on Saturday round opening, downloading data from v5.1 Data - Numerai, and also producing 4 smaller subsampled datasets with non-overlapping data.
numerai latest tournament data is public dataset with output data of producing notebook numerai data. Dataset is updated automatically, when producing notebook is successfully executed.
You can use whichever data source as the input of your notebooks to produce Tournament submissions. Using the new dataset, I have retrained and uploaded all public Kaggle example models:
Hello Numerai automated - basic tutorial model with improved version trained on medium feature set