I got a bit of time today to look at the last 141 features in v4. It’s interesting; it appears that they they are generated in a number of groups. As before, I’m just using the last 350 eras (excluding the final ones that still have nans).
First the correlations among the raw data, not separated by era:
Next:
The correlations between the correlations of the raw features with target 01:
next, a plot of the cumulative sum of the correlations over the 350 eras, which shows interesting behaviour:
particularly the 5 that appear at the top right of the plot
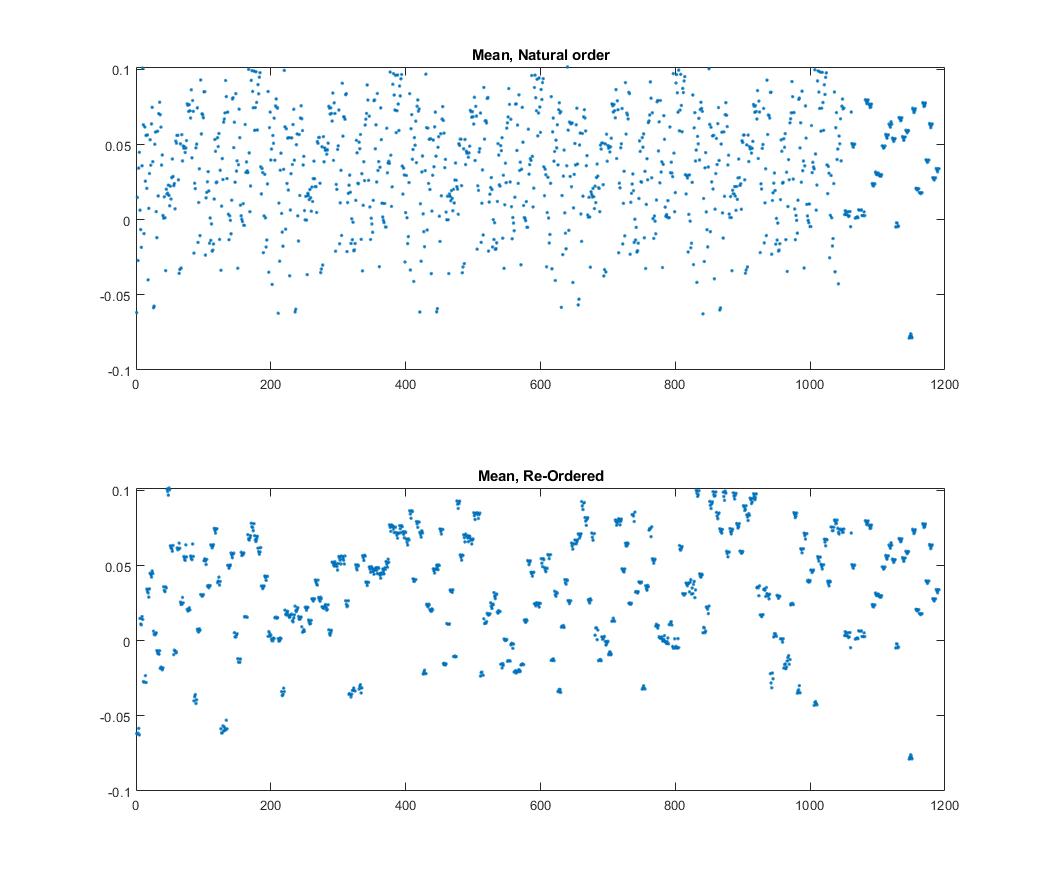
And finally a plot of the mean correlation of each of those features with the target.
There’s some interesting clustering going on!
Added, 16 days later. Apparently Discourse won’t allow more than 3 consecutive posts in a row, so I’ve added what’s below as an edit. I really am not trying to spam this board, I just found these results interesting and hopefully of some use to others. But I’ll desist if that’s preferable.
On the topic of clustering:
I’ve taken a first pass at breaking the raw features into pretty simple clusters, resulting in about 235 of them. Right now it’s hit and miss and by hand, so I don’t expect much.
But I was also curious about the different targets as well. So for this ‘experiment’ (using the term loosely  ) I ran the 235 clusters against all 10 of the 20 day targets (those with an _20 in their names, or for those of us more numerically minded, the evenly numbered target columns from 2 to 20, with all targets being 1 to 21). I only use the most recently completed 350 or so eras.
) I ran the 235 clusters against all 10 of the 20 day targets (those with an _20 in their names, or for those of us more numerically minded, the evenly numbered target columns from 2 to 20, with all targets being 1 to 21). I only use the most recently completed 350 or so eras.
Each cluster, fwiw, is used to generate a Gaussian mixture model from 100 eras from the appropriate target, and then run against the last 250 or so eras of the same target.
That generates interesting results, as shown in the next figure:
Each separate color represents the mean correlation of the output from a different target. So the dark blue points are the results from 235 clusters built from 100 eras of Target #2 and then tested on 250 eras of the same target. The next (red) group are the same clusters but using 100 eras of Target#4, and so on.
I had expected them to be roughly the same, but surprise, surprise, they aren’t. Obviously Targets #12 (light blue) and #14 (maroon) respond rather well! But #6, #10, and #18 do not. 
(Fixed an error in the last sentence, it originally read “…#6, #8, and #10…”. My apologies.)