Tournament 20D2L Scoring
Last month we announced that the Numerai Tournament would begin scoring predictions against a 20D2L target. This change is right around the corner and we wanted to clarify what this means for scores, payouts, and modeling.
It’s important to note that this change does not require any action from you. It does not affect when or what you submit and does not require anyone to retrain their models. The most significant thing users will notice is that our scoring schedule is shifted one day later. For example, rounds will begin scoring on Fridays instead of Thursdays.
We’ve crafted the following diagram to explain how the scoring will work, when scores come out, and what those scores are based on:
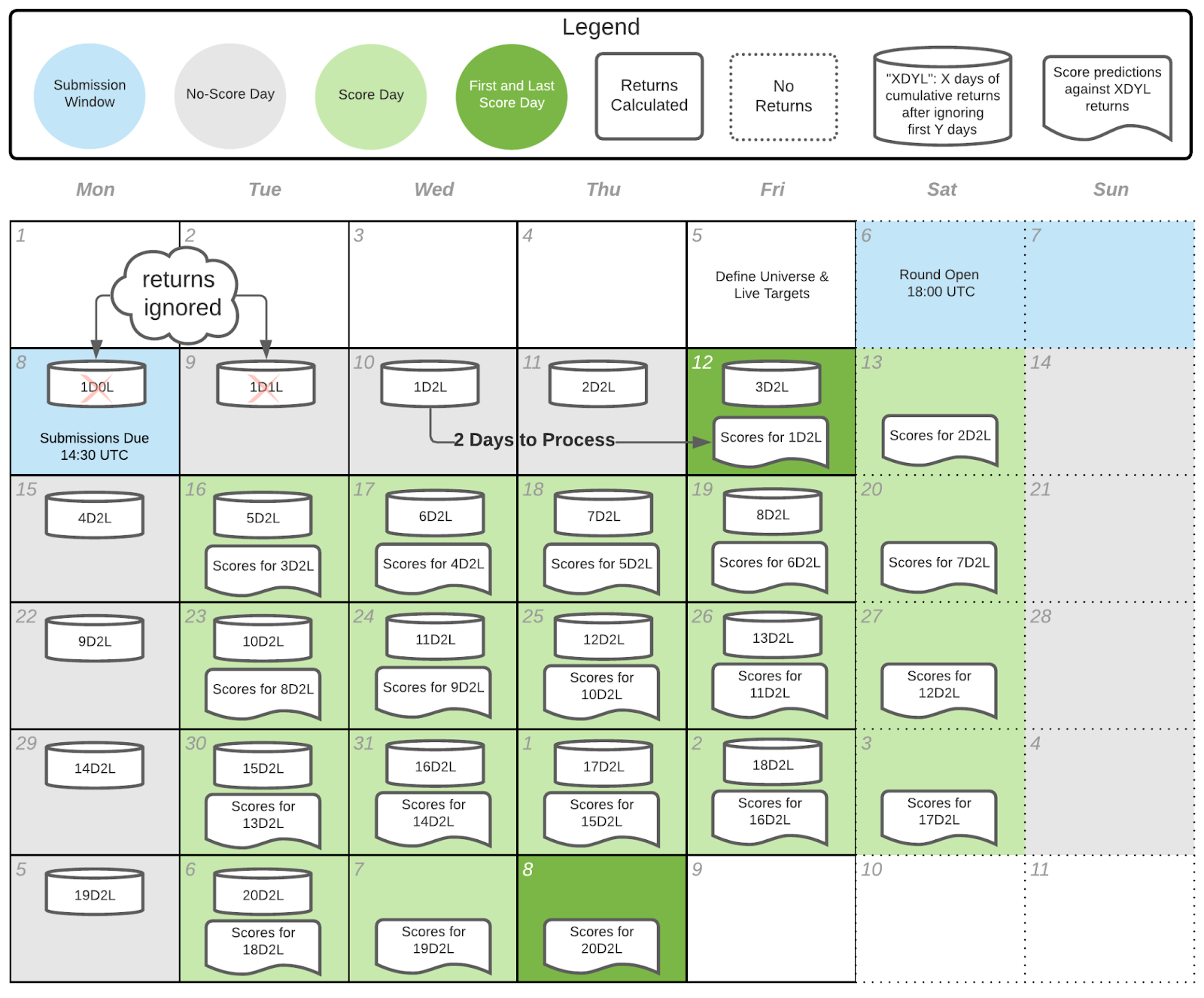
Some things to notice here are:
- There are 20 days of cumulative returns we use to score predictions, i.e. “20D” in 20D2L
- The first two (2) days of returns (Mon/Tues) are ignored, i.e. “2L” in 20D2L
- It takes 2 days to process returns and report scores on them
As compared to our current scoring system (20D1L), you’ll notice the entire schedule is simply shifted one (1) day later. This means the first scoring day of the round will move from Thursdays to Fridays, and newer rounds will resolve on Thursdays, not Wednesday.
It will take 4 weeks to fully transition to this new schedule, during this period:
- Stake changes (increase/decrease/etc.) will take 1 extra day to resolve in the first week
- 20D1L rounds will resolve each Wednesday like normal
- Scores on each Thursday are for 3 overlapping rounds (not 4 like usual)
- The new 20D2L rounds will start scoring each Friday
After this four (4) week transition period ends, we will only have 20D2L rounds actively scoring; round resolution days will be Thursdays and new rounds will start scoring on Fridays.
While this change is primarily a schedule-oriented shift, we would also like to note the difference between 20D1L and 20D2L targets in our data. The “target” in the legacy data (v2) is a 20D1L target and the “target_nomi_20” is a 20D2L target. These targets are 83% correlated in training data and our research indicates that models trained on the legacy 20D1L target perform about as well as those trained on 20D2L target, so the difference in scores and payouts should be very small if you have any models trained and predicting on legacy data. If you have a legacy model and are still concerned about this change, you can read more about the newest dataset here and check out our example scripts (which use the new data) here.
We expect to deploy this change by Round 294.
Numerai Earn
Numerai Earn is a new way for participants to have fun and earn small NMR rewards while learning by completing quests. The first Earn campaign launch will be for Signals only, however we plan to bring this to other tournaments in the future. This is completely optional and is simply a way to encourage Tournament participants to learn more about Signals!
Data Scientists can earn up to 0.08 NMR in stake credits by completing Signals quests such as submitting diagnostics, increasing stake, making a submission, and creating models. Existing Signals participants who have already reached any of these milestones will receive a retroactive airdrop for the stake credits they would have received.
Numerai Earn has been available via the Signals Earn page since December 3. If you haven’t tried Signals yet, this is the time to earn while you learn!
Signals Example Scripts
The Signals example scripts repo has been under construction and will be updated with the launch of the Numerai Earn quests for Signals. The new example scripts repo utilizes OpenSignals which was created by the Council of Elders. It has been simplified and split into two parts: example data pipeline and example model.
Numerai CLI 0.3.3
We’ve released a fix for Numerai CLI with version 0.3.3 that correctly handles Trigger IDs, which are used to ensure your nodes submit correctly. Previously, this caused recently deployed nodes to show an error, but only impacted testing and internal metrics. If you see an error message like “Your node did not submit the Trigger ID …” when running “numerai node test”, then this patch is for you.
It also includes an extra node size option “cpu-xs” which runs your nodes with just 0.5 virtual CPUs and 1 GB of memory. If you’re an efficiency enthusiast that has squeezed every ounce of performance from your code, then you might want to try this out.
Christmas Data Release
Numerai will release some new features on Christmas. We expect a few hundred new features to be added to the dataset. Just like our previous data release, using the new features is optional and will not break any legacy integrations.
The 310 feature set (v2) and the 1050 feature set (v3.1) will still be available through the website and through the API as always. The new feature set (v3.2) will be available in a standalone file only through the API and not through any zip files downloaded via the website. There will be a forum post with more information when the data becomes available, so be on the lookout!